1. LangChain4j 简介
概念
LangChain4j 是一个开源的 Java 库/框架,用来简化在 Java 应用中集成和使用大型语言模型的过程。它的设计目标是让 Java 开发者能够像使用 Python 的 LangChain 那样,轻松构建复杂的 AI 应用(比如聊天机器人、智能助手、检索增强生成系统等)。
特点
LLM 集成:提供统一的 API,让你可以调用多种主流的大语言模型(如 OpenAI、Google、Anthropic、国产模型等),而无需直接对接各自的低级接口。
模块化与扩展性:框架采用模块化设计,不同的组件可以单独引入,例如模型提供商、向量数据库、记忆管理、工具调用等。
RAG 支持(检索增强生成):将外部文本数据转化为向量,结合向量数据库进行语义检索,并将结果注入模型上下文以提升回答质量。
工具与 Agents:支持函数调用、外部工具集成以及智能体工作流(Agents),构建更复杂的 AI 任务流程。
与 Java 生态集成:可以与常见的 Java 框架(如 Spring Boot、Quarkus)结合使用。
2. Java 语言整合 LangChain4j
引入依赖
我们首先创建一个基本的 Java 项目,我这里以 Maven 项目为例。
首先引入 LangChain4j 的核心框架依赖和适配实现依赖 (这里使用 OpenAI 的适配实现),如下所示:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
<version>${langchain4j.version}</version>
</dependency>
具体版本的特点,以及其他接口规范的依赖(如阿里、Ollama等)可以参考 官方开源仓库 或 官方文档,他们的使用方法基本和 OpenAI 的一致。
然后我们再引入 Junit 的依赖,便于进行单元测试:
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.11.4</version>
<scope>test</scope>
</dependency>
文生文快速入门 Demo
然后我们写一个单元测试就可以快速掌握 LangChain4j 的使用方法:
@Test
public void test1() {
ChatModel model = OpenAiChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName("gpt-4o-mini")
.build();
String answer = model.chat("你好");
System.out.println(answer);
}
如果你有 OpenAI 的 api 密钥,可以直接运行该测试单元,查看结果,就可以输出模型返回的结果。
需要注意的是,ChatModel API 是在 LangChain4j 1.0.0-beta4 版本中引入的。在此之前的版本中,应使用 ChatLanguageModel 作为对话模型的规范接口。
如果我们使用的是其他的一些第三方的 API,如果其也满足 OpenAI 的接口规范,我们可以使用 OpenAiChatModel 中的 baseUrl 方法,来填写第三方 API 接口地址,具体接口地址格式需要根据第三方接口的接口文档来进行规范,但不应包含具体的资源路径,例如, 如果我们使用硅基流动的接口:
@Test
public void test1() {
ChatModel model = OpenAiChatModel.builder()
.baseUrl("https://api.siliconflow.cn/v1")
.apiKey(System.getenv("SILICONFLOW_API_KEY"))
.modelName("Qwen/Qwen3-30B-A3B-Instruct-2507")
.build();
String answer = model.chat("你好");
System.out.println(answer);
}
运行后结果如下:
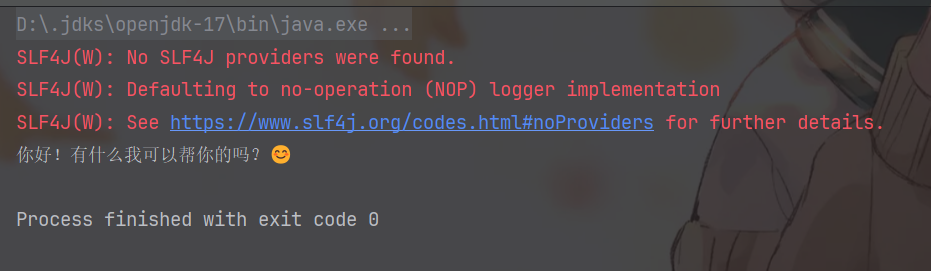
可以看到,成功打印出模型返回的结果,还带着一个非常可爱的 emoji 表情 😊。
上述红色警告可以暂时忽略,这是因为当前项目尚未配置具体的日志实现。从 LangChain4j 核心框架的依赖树可以看出,它仅引入了 slf4j 作为日志门面,而未绑定任何具体的日志实现。后续在集成 Spring Boot 项目时,Spring Boot 默认提供的日志实现会自动补齐这一部分:
如果不打算集成 Spring Boot 项目,可以手动引入 Logback 作为日志实现来消除该警告。实际上,Spring Boot 默认已经集成并自动配置了 Logback 作为日志实现,因此在 Spring Boot 项目中通常不会遇到该问题。
但是我们现在仅仅做测试,不用日志系统也是没问题的。
文生图快速入门 Demo
对于文生图,使用的是 ImageModel,我这里使用阿里的 Qwen-Image 的文生图模型,这里我们直接调用 ImageModel 下的 generate 方法,传入我们的文本描述即可,比如我想生成一个“猫耳萌妹子”的图片,我们就传入这个字符串,返回的是一个 Response 数据,我们可以使用 response.content().url() 获得生成的图片的直链。
@Test
public void test2() {
ImageModel model = OpenAiImageModel.builder()
.baseUrl("https://api.siliconflow.cn/v1")
.apiKey(System.getenv("SILICONFLOW_API_KEY"))
.modelName("Qwen/Qwen-Image")
.build();
Response<Image> response = model.generate("猫耳萌妹子");
System.out.println(response.content().url());
}
运行结果如下:
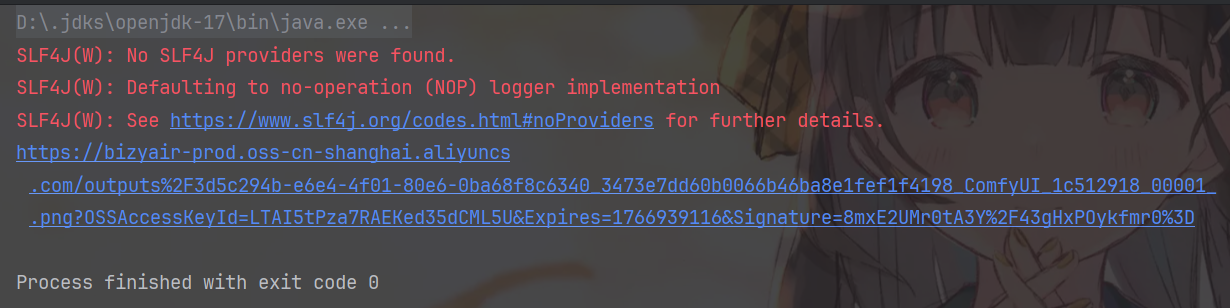
我们把打开链接,下载图片,得到的图片如下:

可见质量非常不错,非常符合我们的要求。
在此基础上,其他模态方向的能力(例如文生语音、图生文、图生视频等)读者可以结合所选平台的 API 文档进一步探索。需要注意的是,不同厂商对多模态能力的接口设计差异较大:有的平台提供 OpenAI-compatible 的扩展端点,有的平台则采用各自的多模态协议或工作流编排接口。实际落地时建议优先选择接口稳定、文档清晰且生态成熟的方案。
3. LangChain4j 整合 Spring Boot
快速入门 Demo
使用 LangChain4j 整合 Spring Boot,首先要求我们的 Spring Boot 版本必须 3.2 版本及以上,且 JDK 版本要求 17 及以上。原文细节
LangChain4j 主要提供了两类 Starter,分别是:
- 集成类 Starter:用于对接常见的模型提供方、向量数据库、Embedding 服务等第三方组件,提供相应的自动装配与配置能力,便于在 Spring Boot 中开箱即用。
- 声明式 AI Services Starter:用于启用和增强声明式 AI Service 能力(如
@AiService),支持以接口/注解方式定义 AI 能力,并由框架完成实现生成、依赖注入与运行时编排。
集成类 Starter
这样说比较干燥,我们来先看第一类 Starter。这一类的 Starter 的统一具体格式为:langchain4j-{integration-name}-spring-boot-starter,其中 {integration-name} 表示具体的集成对象(例如某个大模型提供方、Embedding 服务或向量数据库等)。例如我这里用 OpenAI 的统一接口规范,就可以引入如下依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
<version>1.10.0-beta18</version>
</dependency>
这里的 {integration-name} 就是 open-ai,对于其他提供方的具体名称格式,可以参考官方仓库。
引入依赖之后,下面就是振奋人心的书写配置信息的阶段。我们可以在 application.properties 中书写,也可以在 application.yml 等格式文件中书写。
倘若在 application.properties 中书写,基本需要加入以下内容:
langchain4j.open-ai.chat-model.api-key=${OPENAI_API_KEY}
langchain4j.open-ai.chat-model.model-name=gpt-4o
langchain4j.open-ai.chat-model.log-requests=true
langchain4j.open-ai.chat-model.log-responses=true
...
这里为什么要用三个点,这是上述四个是基本的配置信息,第一个是密钥信息,第二个是模型信息,第三个是开启把发给模型的请求内容打到日志里,第四个是开启把模型返回的响应内容打到日志里。
还有一些其他的配置项也可以参与配置,具体请参考官方的 api 文档。
比如,我现在要用硅基流动的接口,所以我还需要一个 base-url 的配置项,所以总体配置就是:
langchain4j.open-ai.chat-model.api-key=${SILICONFLOW_API_KEY}
langchain4j.open-ai.chat-model.model-name=Qwen/Qwen3-30B-A3B-Instruct-2507
langchain4j.open-ai.chat-model.base-url=https://api.siliconflow.cn/v1
langchain4j.open-ai.chat-model.log-requests=true
langchain4j.open-ai.chat-model.log-responses=true
然后我们写一个测试 Controller,如下:
@RestController
public class ChatController {
private ChatModel chatModel;
public ChatController(ChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/chat")
public String model(@RequestParam(value = "message", defaultValue = "Hello") String message) {
return chatModel.chat(message);
}
}
在这种情况下,Controller 只依赖接口 ChatModel,具体实现由 starter 自动创建一个实例OpenAiChatModel,来实现自动装配和注入,非常的方便。
然后我们编写测试单元进行测试:
@Autowired
private ChatController chatController;
@Test
void test4(){
System.out.println(chatController.model("你好,你是谁?"));
}
运行结果如下:
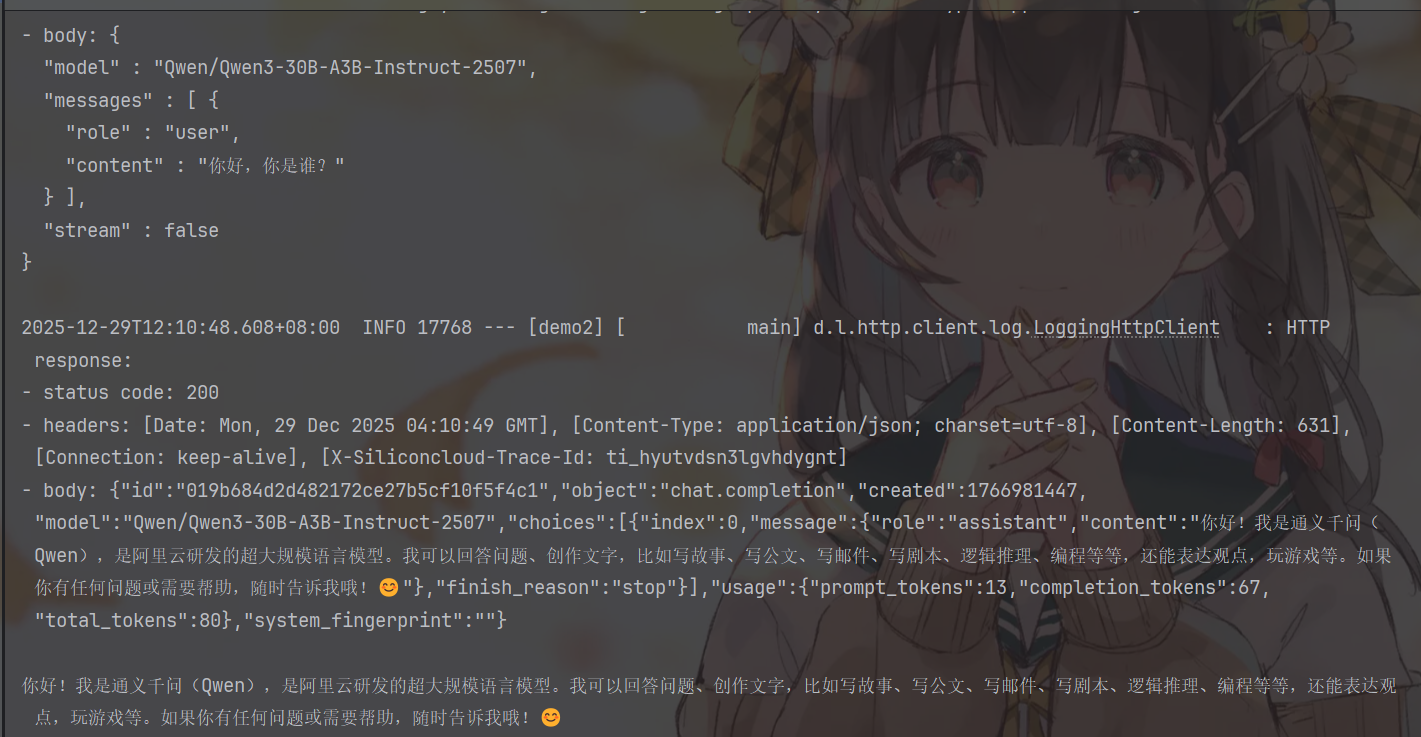
可以看到,不仅有我们 sout 的输出结果,还有请求与响应内容的日志打印,这是我们前面在配置文件里开启的两个 log 的结果。
在实际的项目开发中,我们可以根据我们的需求个性化定义工具类,例如:
@AllArgsConstructor
@Component
public class AIUtil {
private final ChatModel chatModel;
public String generateText(String content){
return chatModel.chat(content);
}
}
这样就非常的优雅。记得要加上 @Component 注解交给 IoC 容器管理。
我们前面的所有测试,都是等接口完全生成完文本之后,才获得结果,然后打印,但是我们在网页中使用 AI 进行对话的时候,它的输出往往是流式的,例如:

可以看到,他是一个词一个词的往外崩的,并不是把所有内容都获取完毕才返回给我们。这种输出方式通常被称为流式输出,其核心思想是:模型在生成内容的过程中,每产生一个 token(或一个文本片段),就立刻返回给调用方,而不是等待完整响应生成完成。
对于 Web 场景下的 AI 对话来说,流式输出几乎是“标配”,它可以显著提升用户体验:
- 更低的首字延迟:用户几乎立刻就能看到模型开始“说话”
- 更自然的交互感:更接近真人输入的节奏
- 更适合长文本生成:避免长时间白屏等待
接下来,我们就来看一下 LangChain4j + Spring Boot 场景下,如何优雅地实现流式输出。
在 LangChain4j 中,流式输出并不是通过 ChatModel 来完成的,而是通过专门的 Streaming 接口,例如 StreamingChatModel。当使用符合对应模型提供商规范的接口时,LangChain4j 会在底层通过 SSE(Server-Sent Events) 与模型建立流式连接,并将模型在生成过程中产生的 token 增量 逐个回调给调用方。
好在这些复杂的底层细节,我们并不需要手动处理。
LangChain4j 的 Spring Boot Starter 已经为我们封装好了对应的自动配置能力,会根据配置文件自动创建并注册 StreamingChatModel 相关的 Bean。
首先,我们需要在 application.properties 中补充流式模型的配置。与前面同步调用使用的 chat-model 不同,这里使用的是 streaming-chat-model 前缀,如下:
langchain4j.open-ai.streaming-chat-model.api-key=${SILICONFLOW_API_KEY}
langchain4j.open-ai.streaming-chat-model.model-name=Qwen/Qwen3-30B-A3B-Instruct-2507
langchain4j.open-ai.streaming-chat-model.base-url=https://api.siliconflow.cn/v1
langchain4j.open-ai.streaming-chat-model.log-requests=true
langchain4j.open-ai.streaming-chat-model.log-responses=true
然后我们改造一下工具类:
@AllArgsConstructor
@Component
public class AIUtil {
private final StreamingChatModel streamingChatModel;
public void generateText(String content, StreamingChatResponseHandler handler){
streamingChatModel.chat(content,handler);
}
}
就是把原来的 ChatModel 改成 StreamingChatModel,然后 chat 方法里传入一个回调处理器:StreamingChatResponseHandler。改动非常微小。
现在 Spring Boot 做流式返回已经不需要自己手写 SSE 细节了,我们只需要引入 Spring WebFlux 的依赖,即可方便地通过返回 Flux 实现服务端数据的自动分片、实时推送与连接管理,Spring 会负责底层的 SSE 协议封装与刷新逻辑。
Spring WebFlux 的依赖格式如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
我们以最快的速度写一个 Service 和 Controller 进行测试,如下:
@Service
public class ChatServiceImpl implements ChatService {
@Autowired
private AIUtil aiUtil;
@Override
public Flux<String> chat(String content) {
return Flux.create(e->aiUtil.generateText(content, new StreamingChatResponseHandler() {
@Override
public void onPartialResponse(String partialResponse) {
e.next(partialResponse);
}
@Override
public void onCompleteResponse(ChatResponse chatResponse) {
e.next(" 输出完毕。");
e.complete();
}
@Override
public void onError(Throwable throwable) {
e.next(throwable.getMessage());
}
}));
}
}
@RestController
public class ChatController {
@Autowired
private ChatService chatService;
@GetMapping(value = "/chat", produces = "text/event-stream;charset=UTF-8")
public Flux<String> chat(@RequestParam("message") String content) {
return chatService.chat(content);
}
}
接着,我们打开 ApiFox 进行测试,我们输入我们的测试 url:http://localhost:8080/api/chat?message=你好,你是谁,可以看到返回的结果一个词一个词的蹦了出来:
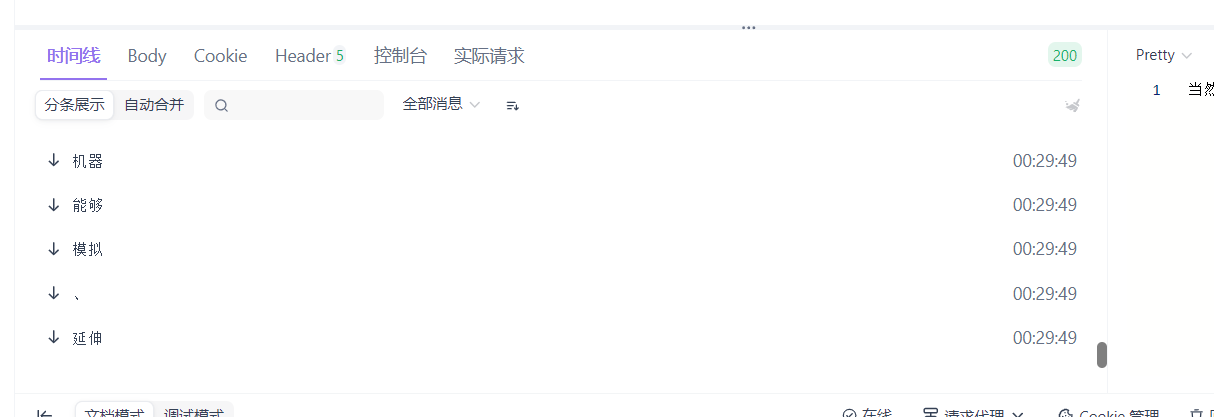
从运行结果可以看出,web 端能够逐段接收实时返回的内容,这正是 StreamingChatResponseHandler 各个回调方法协同工作的结果。下面我们逐一分析这些回调在流式输出中的作用。
StreamingChatResponseHandler 的几个回调方法分别对应了模型生成过程中的不同阶段:在模型尚未完全生成结果时,onPartialResponse 会被多次触发,每次返回一小段内容,我们在这里通过 FluxSink.next() 将数据立即推送给下游,从而实现前端页面中文字的实时输出;当模型生成结束后,会回调 onCompleteResponse,用于标识本次生成已经完成,实际使用中通常在这里结束流;如果在生成过程中发生异常,则会触发 onError,用于将错误信号传递给前端。正是通过 Flux.create 将这种回调式的流转为 Flux,Spring WebFlux 才能够自动以流式的方式将数据持续写入 HTTP 响应中,最终实现无需手写 SSE 的流式输出效果。
除上述三个主要的回调方法之外,还有一个 onPartialThinking 方法。这个方法是做什么的呢?
我们发现,现在其实很多模型都是带思考过程的,就是先进行思考推理,这个回调其实就是来处理推理过程返回的内容的,这里就不再继续讨论,原理和 onPartialResponse 类似,感兴趣的朋友可以继续探究,事实上在后面我们还有更简洁的回调写法,在后面我们再继续探究。
声明式 AI Services Starter
LangChain4j 提供了一个 Spring Boot starter,用于自动配置 AI 服务、RAG、工具等。
我们已经完成了底层模型客户端的自动装配,但如果仍然停留在直接注入 ChatModel、手写 Prompt 和回调逻辑这一层,整体使用方式依然偏向命令式。AI Services Starter 的意义在于进一步抽象这些样板代码,让你可以像编写普通 Spring Service 一样,通过声明式接口来使用大模型能力。你只需要定义方法签名和注解,LangChain4j 就会在运行时自动生成实现,负责 Prompt 构建、模型调用以及结果映射等细节。配合 Spring Boot 的自动配置,模型参数和密钥都可以集中在 application.yml 中统一管理,也便于在不同环境或模型之间切换。当引入 RAG 或工具调用时,这种方式的优势会更加明显,相关编排对业务代码几乎是透明的,使代码始终保持简洁、清晰和可维护。
接下来,我们快速来演示一下在代码中的具体使用。
首先我们要导入 langchain4j-spring-boot-starter 的依赖,如下:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.10.0-beta18</version>
</dependency>
<!-- langchain4j-reactor 是 LangChain4j 对 Reactor(Mono / Flux)的官方适配层,-->
<!-- 因为我们流式输出用到了 Flux,这里需要引入下面这个适配层依赖,如果你的项目中不需要流式-->
<!-- 输出,则不需要引入下面这个依赖,只需要引入上面的依赖即可。-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.10.0</version>
</dependency>
然后我们把 ChatServiceImpl 注释掉或删除掉就可以了,我们不用手动去实现这么繁琐的代码,我们直接回到 ChatService 接口中,给它添加上 AiService 注解,如下:
@AiService
public interface ChatService {
Flux<String> chat(String content);
}
其它代码不需要改动,我们再去运行去 ApiFox 测试一下:
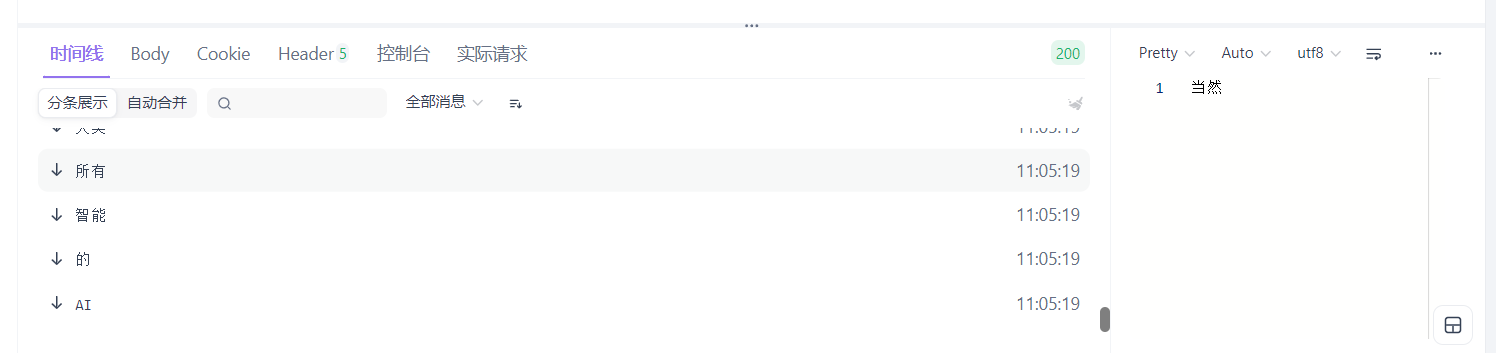
可以看到和我们料想的一样,可以正确给出流式响应,而且不需要我们自己去书写那些繁琐的实现类代码了。
那我们回过头来,去看一下 @AiService 的源码,看看它到底为我们做了什么。源码如下:
@Service
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface AiService {
AiServiceWiringMode wiringMode() default AiServiceWiringMode.AUTOMATIC; // 装配模式:自动或手动指定依赖
String chatModel() default ""; // 同步 ChatModel 的 Bean 名称
String streamingChatModel() default ""; // 流式 StreamingChatModel 的 Bean 名称
String chatMemory() default ""; // ChatMemory Bean 名称,用于对话记忆
String chatMemoryProvider() default ""; // ChatMemoryProvider Bean 名称,按会话创建记忆
String contentRetriever() default ""; // ContentRetriever Bean 名称,用于 RAG 检索
String retrievalAugmentor() default ""; // RetrievalAugmentor Bean 名称,封装完整 RAG 增强流程
String moderationModel() default ""; // ModerationModel Bean 名称,用于内容安全审查
String toolProvider() default ""; // ToolProvider Bean 名称,用于统一提供工具
String[] tools() default {}; // 指定要注入的工具 Bean 名称列表
}
可以看到,AiService 中,又封装了 Service 注解,因此,使用 AiService,就相当于使用了 Service 注解,因此会被 Spring 扫描并纳入 IoC 管理。不过当它标注在接口上时,Spring 注入的并不是接口本身,而是 LangChain4j 根据注解配置在运行时生成的代理实现,关于动态代理的知识点,可以参考我的另一篇博客;这个代理会负责 Prompt 组装、模型选择(chat/streaming)、记忆/RAG/工具等能力的编排,从而让接口方法看起来像普通 Service 调用,但底层实际是在调用大模型。我们来看一下它动态代理部分的源码,位于 dev.langchain4j.service.DefaultAiServices 下:
@Internal
class DefaultAiServices<T> extends AiServices<T> {
...
public T build() {
validate();
Object proxyInstance = Proxy.newProxyInstance(
context.aiServiceClass.getClassLoader(),
new Class<?>[]{context.aiServiceClass},
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// Object / default 方法处理
if (method.isDefault()) {
return InvocationHandler.invokeDefault(proxy, method, args);
}
if (method.getDeclaringClass() == Object.class) {
...
}
// 构建一次 AI 调用上下文
InvocationContext invocationContext = InvocationContext.builder()
.invocationId(UUID.randomUUID())
.interfaceName(context.aiServiceClass.getName())
.methodName(method.getName())
.build();
// 核心入口:将接口方法调用转为 AI 调用
return invoke(method, args, invocationContext);
}
public Object invoke(Method method, Object[] args, InvocationContext invocationContext) {
// Prompt / Memory / RAG / Guardrails 等准备
...
// 判断是否为流式返回
Type returnType = method.getGenericReturnType();
boolean streaming =
returnType == TokenStream.class || canAdaptTokenStreamTo(returnType);
if (streaming) {
// 流式:返回 TokenStream 或适配后的类型(如 Flux)
TokenStream tokenStream = new AiServiceTokenStream(...);
return returnType == TokenStream.class
? tokenStream
: adapt(tokenStream, returnType);
}
// 非流式:同步调用模型并解析结果
ChatResponse response = chatModel.execute(...);
return serviceOutputParser.parse(response, returnType);
}
}
);
return (T) proxyInstance;
}
...
}
同时,我们注意到 AiService 中还提供了很多注解属性供我们使用,我们这里只做快速入门,其他属性的具体作用,后期我会单独开文章进行详细的讲解。