这篇论文是 AAAI-2024 的文章,文章的标题是”Differentiable Auxiliary Learning for Sketch Re-Identification” (可微分辅助学习在草图重识别中的应用)。
论文提出了一种名为 DALNet 的网络架构。该方法通过对真实照片进行背景去除和边缘检测强化,生成一个”类草图“的中间辅助模态,以此来桥接并对齐草图与照片模态 。由于负责生成这一辅助模态的模块是可训练且可微分的,支持端到端优化,因此该方法被命名为”可微分辅助学习”(Differentiable Auxiliary Learning, 简称 DAL)。
1. 动机
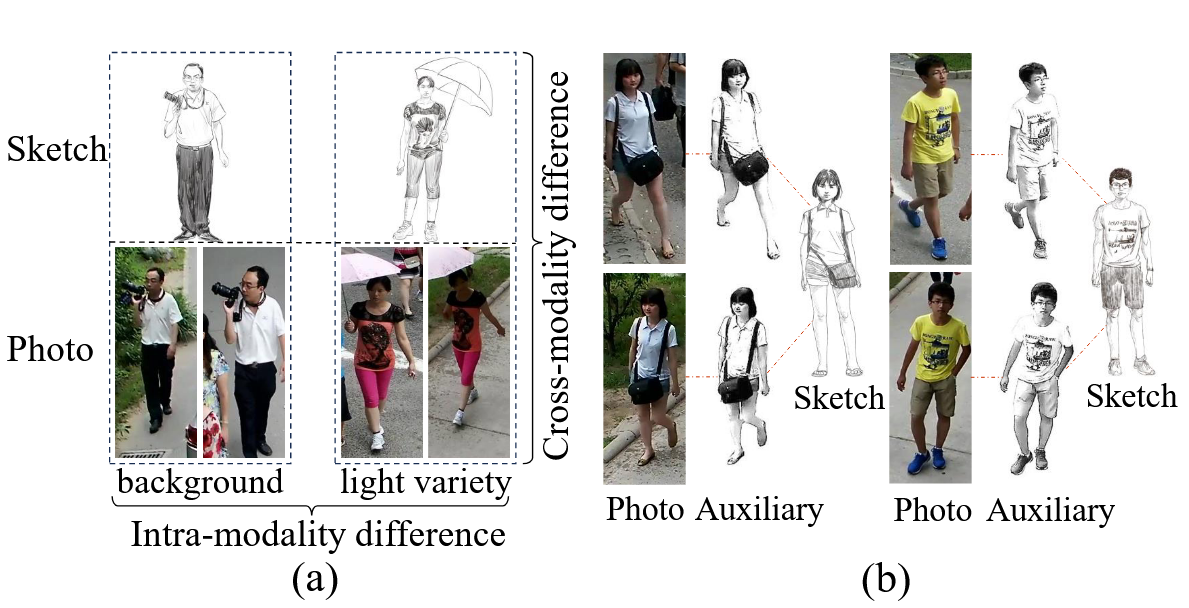
如上图,论文的动机非常明确,可以分为两大点:
- 草图与行人图像之间模态间差异太大,能否构建一个中间模态来辅助打破两种模态的差异鸿沟。
- 草图与行人图像各自模态内差异也很大,首先同一个行人的草图可能有不同画师绘制,风格多样,抽象程度差异大;并且同一个行人在不同摄像头下的照片,会受到背景杂波、光照变化以及视角姿态差异的严重干扰 。这导致即便是同一个人的照片,在特征空间中也可能相距甚远,增加了匹配难度。
为解决第一个问题,论文构建了一个“类草图”的中间辅助模态作为桥梁。该模态通过对真实照片进行背景去除与边缘检测增强生成,从而有效地辅助建立了模态间的特征对齐 。论文在特征学习阶段加入多模态协同约束:用跨模态的 circle loss 让草图、照片与类草图三者关系整体对齐。
为解决第二个问题,论文又引入模态内的 circle loss 专门压缩同一模态中同身份的分布、拉开不同身份的距离,从而对草图来说,减弱不同画师风格造成的影响;对真实图像来说,减弱光照背景与视角姿态变化等带来的特征漂移问题。
2. 方法
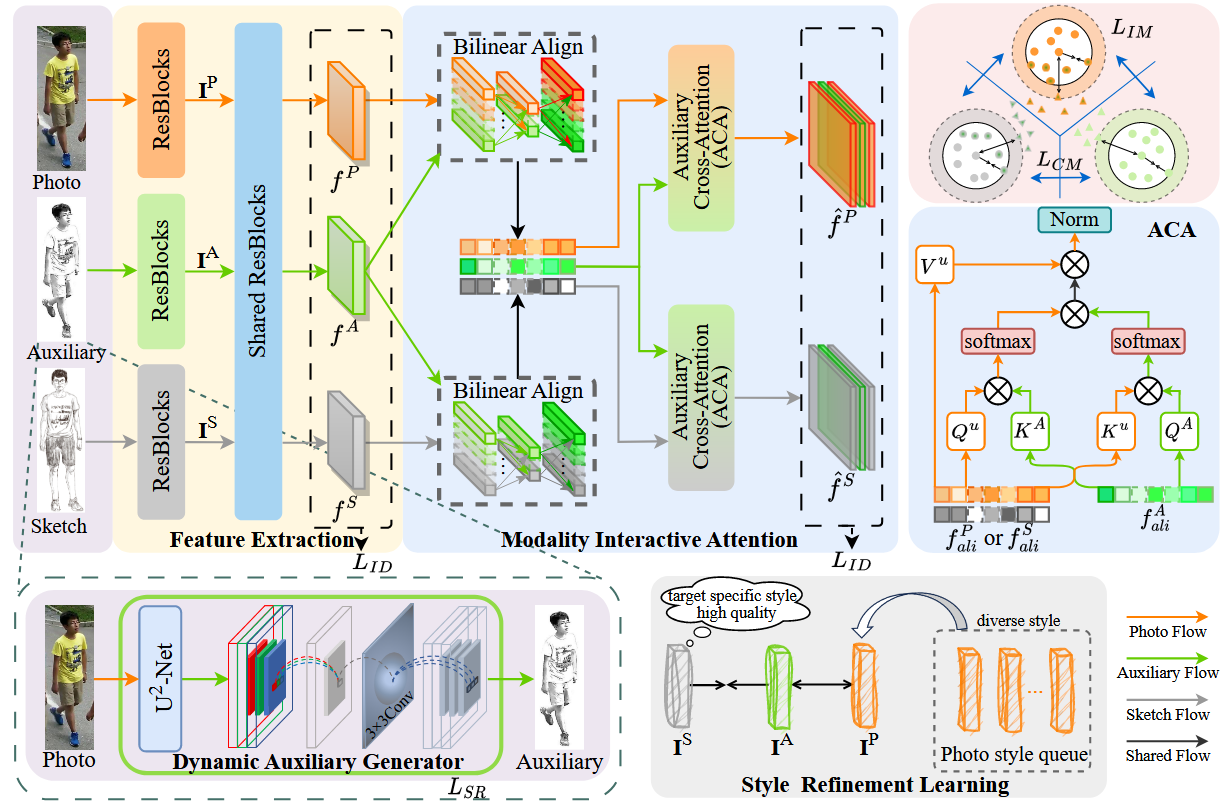
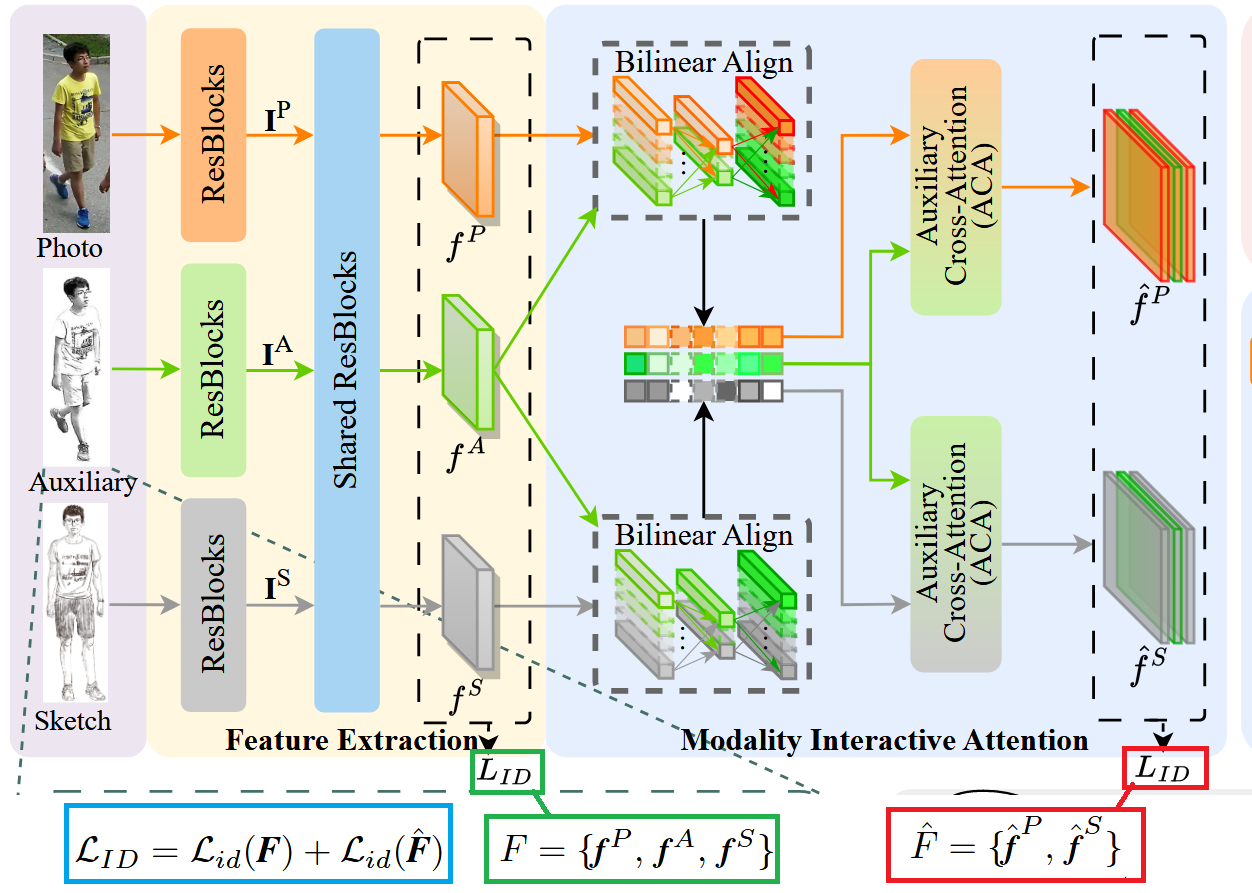
模型的总体框架图如上图所示,整体来说,训练阶段首先使用 Dynamic Auxiliary Generator (DAG) 模块生成一个类草图的辅助模态图像 (这个模块是可循练的,通过 损失来优化这个模块,使得生成的辅助图像自适应逼近目标草图风格),然后把草图、辅助图像和真实图像三个模态的图像进行编码,提取特征,然后把辅助模态的特征融合到另外两个模态当中去,并通过交叉注意力机制,强化草图与真实图像之间共享语义信息、实现细粒度交互融合。最后结合分类损失与跨模态/模态内 circle loss 来共同约束三模态的特征关系与分布,下面我来分析一下各部分的细节。
Dynamic Auxiliary Generator (DAG)
这是动态辅助生成器模块,作用就是输入一张真实图像,输出一张类草图的辅助图像。其原理具体如下图所示:
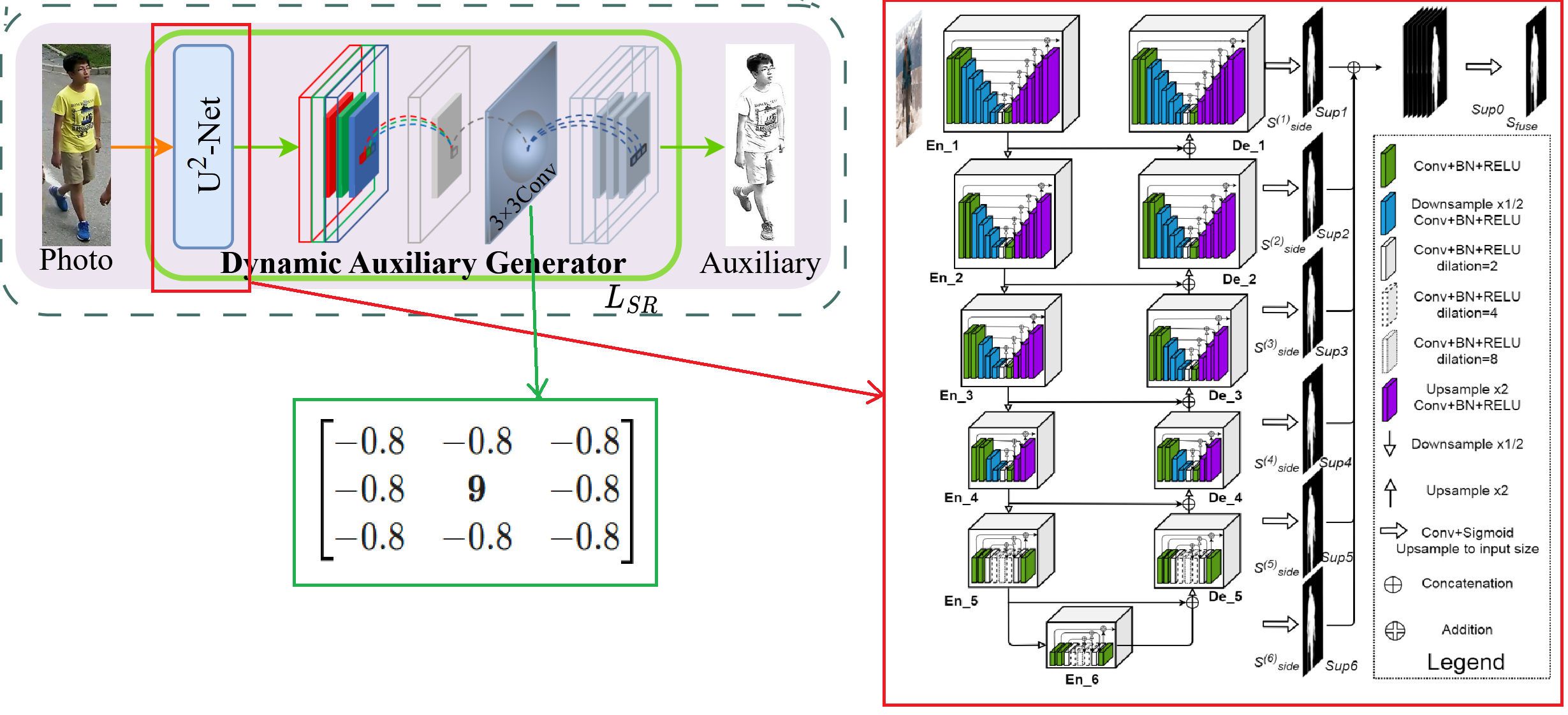
首先,将真实行人图像输入预训练的 U²-Net(该网络参数保持冻结)得到前景分割的掩码矩阵;再利用该掩码对原图进行逐像素筛选,从而保留行人主体并去除背景,得到背景被抠除的行人图像。U²-Net 的具体结构如上图右侧所示,之所以叫 U²-Net,是因为它在整体上是一个 U-Net 式的编码器-解码器结构,但其每个编码与解码阶段内部又嵌套了一个更小的 U-Net(即 RSU 模块,Residual U-block),相当于“U 中套 U”,形成两层 U 形结构的级联,因此用 U 的平方来命名。
U²-Net 会在解码过程中从不同尺度的侧输出层生成多张掩码(side maps),这些掩码分别对应不同分辨率下对前景的预测:浅层侧输出更关注边缘与细节,高层侧输出更关注整体结构与语义区域;训练时通常对这些侧输出施加深度监督以稳定收敛、提升多尺度分割能力,最后再将多尺度侧输出进行融合(如拼接后卷积或加权融合)得到一张最终的高质量前景掩码,用于后续的背景抠除。
得到抠除背景的行人图像后,此时仍然是一个 RGB 的彩色图像,因此首先要通过一个 1×1 的卷积块将其转化为单通道的灰度图像,然后经过一个 3×3 的卷积核,进行边缘检测,强化轮廓线条,使灰度图更加逼近于草图,从而生成类草图的辅助模态图像。这其中,这个 3×3 的卷积核是可循练的,这个也是 DAG 模块唯一可训练优化的地方,通过损失函数 进行约束,该损失函数的定义我会在下面的特征提取模块中进行详细的分析。卷积核初始化为中心数字为 9,周围 8 个数字为 -0.8,先提供一个稳定的“边缘增强”先验,再在训练过程中根据下游检索目标自适应调整卷积核权重,使生成的 Auxiliary 更符合草图域的轮廓表达方式。
Featrue Extraction
然后是特征提取模块,如下图所示,整体采用一个三流的 ResNet-50 作为 backbone,分别对 Photo、Auxiliary 和 Sketch 三种模态进行特征编码:每个模态先经过各自的前端 ResBlocks (使用的 ResNet-50 的前两个阶段) 提取低层局部特征,得到三路的全局表征;随后再把三路特征送入同一套“权重共享”的后续 ResBlocks (使用的是 ResNet-50 后面剩余的阶段),学习更高层、更接近语义的共享表示,为后面的模态交互对齐做准备。
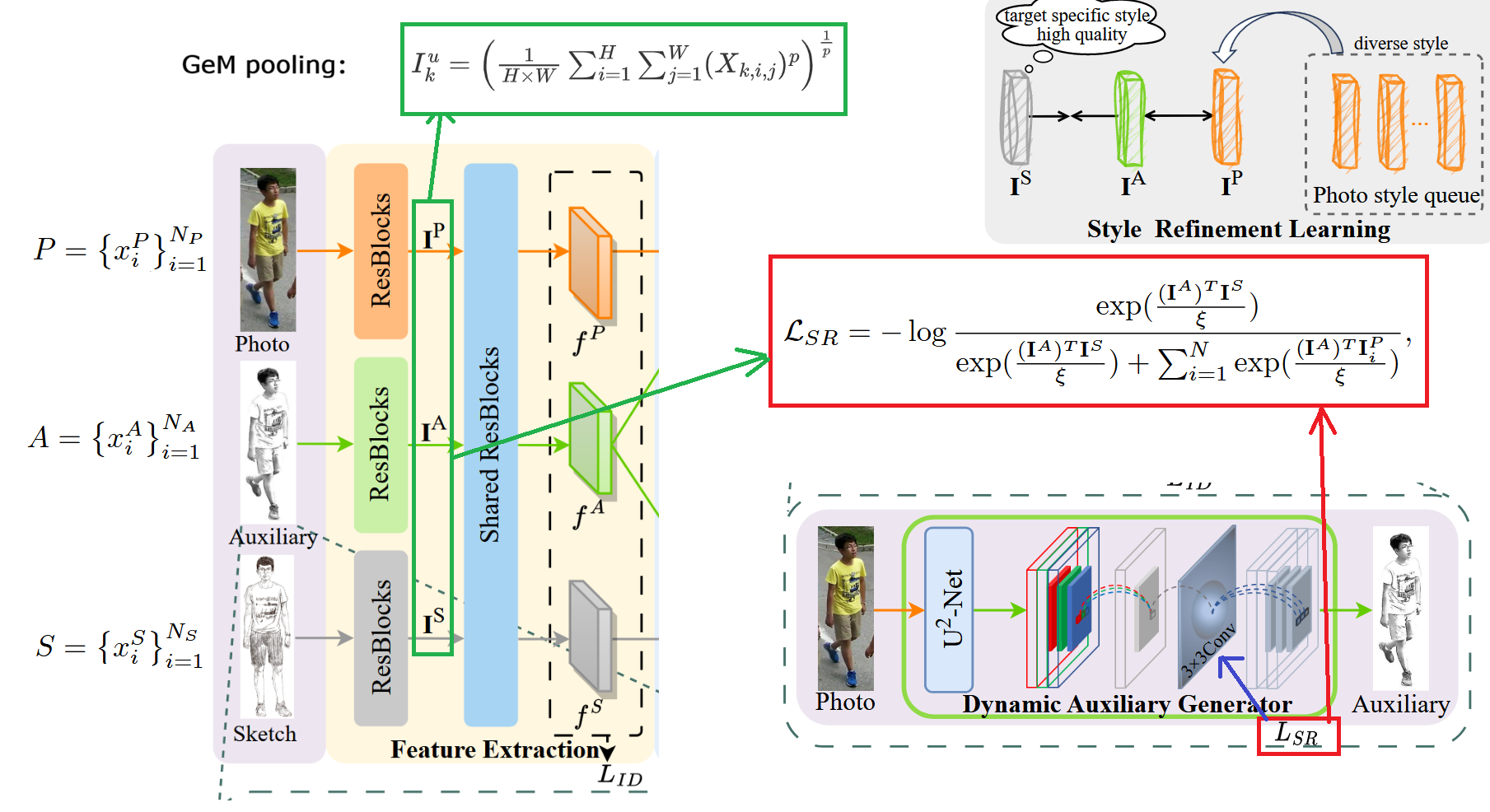
具体来看,定义 为真实图像的样本集合, 表示样本数量, 与 集合也是同理,分别表示类草图集合和草图集合。
现将 Photo、Auxiliary 和 Sketch 放入各自的前端 ResBlocks 得到三个编码后的特征图,对这些特征图进行 Gem Pooling 池化操作,分别得到三个池化后的特征向量 , 和 。具体公式如上图的 所示,其中 表示模态, 表示当前为第 个通道, 和 分别代表特征图的高和宽, 是一个可学习的参数, 接近为 时,池化会更像“平均池化”(对整幅特征图做更均匀的聚合);而当 逐渐变大时,聚合过程会越来越接近“最大池化”(更强调响应最强的位置)。之所以使用 GeM Pooling,是因为它用一个可学习的 在平均池化与最大池化之间自适应折中:既能保留全局结构信息,又能突出对行人检索更关键的局部判别区域(如衣服纹理、轮廓细节等),从而在跨模态匹配时获得更稳健、判别性更强的全局表征。
得到的三个特征向量后,论文计算风格细化损失函数 (其形式与 InfoNCE 类似),具体公式如上图所示,目的是把 DAG 生成的辅助模态 Auxiliary 从“照片风格”拉向“草图风格”,从而优化 DAG 模块的卷积核参数,但又不破坏它继承自 Photo 的人体结构信息。具体做法是:以辅助模态的风格特征 作为锚点,把同一身份对应的草图风格特征 当作唯一的正样本;分母中只放入 与一组照片风格特征 来做对比,而不额外加入其他草图特征,是因为这里并不是要学习“草图之间”的可分性(那属于身份判别和检索损失去处理),而是要明确地把 从 Photo 域中区分出来并向 Sketch 域靠拢:如果分母再引入大量“其他草图”,优化会变成让 同时远离这些草图(包括与目标草图风格相近的草图),容易削弱“向草图域靠近”的牵引力,甚至引入不必要的身份与风格混杂。因而该损失的对比集合被刻意设计为“一个草图正样本 + 多个照片负样本”,通过温度系数 的 softmax 归一化最大化 与 的相似度、最小化 与各 的相似度,从而实现“去照片风格化 + 向草图风格对齐”的风格迁移约束。实验细节里给出温度系数 取值为 0.07。
之后,三路的特征图送入同一套“权重共享”的后续 ResBlocks,学习更高层、更接近语义的共享表示,具体表示为 , 和 ,为后面的模态交互对齐做准备。这里注意,送入到后续的 ResBlocks 的是原来三路生成的特征图,而不是池化后的 。
Modality Interactive Attention (MIA)
然后是模态交互注意力模块。具体如下图所示。该模块又具体分为两个模块组成,一个是 Bilinear Align 模块,一个是 Auxilirary Cross-Attention 模块。
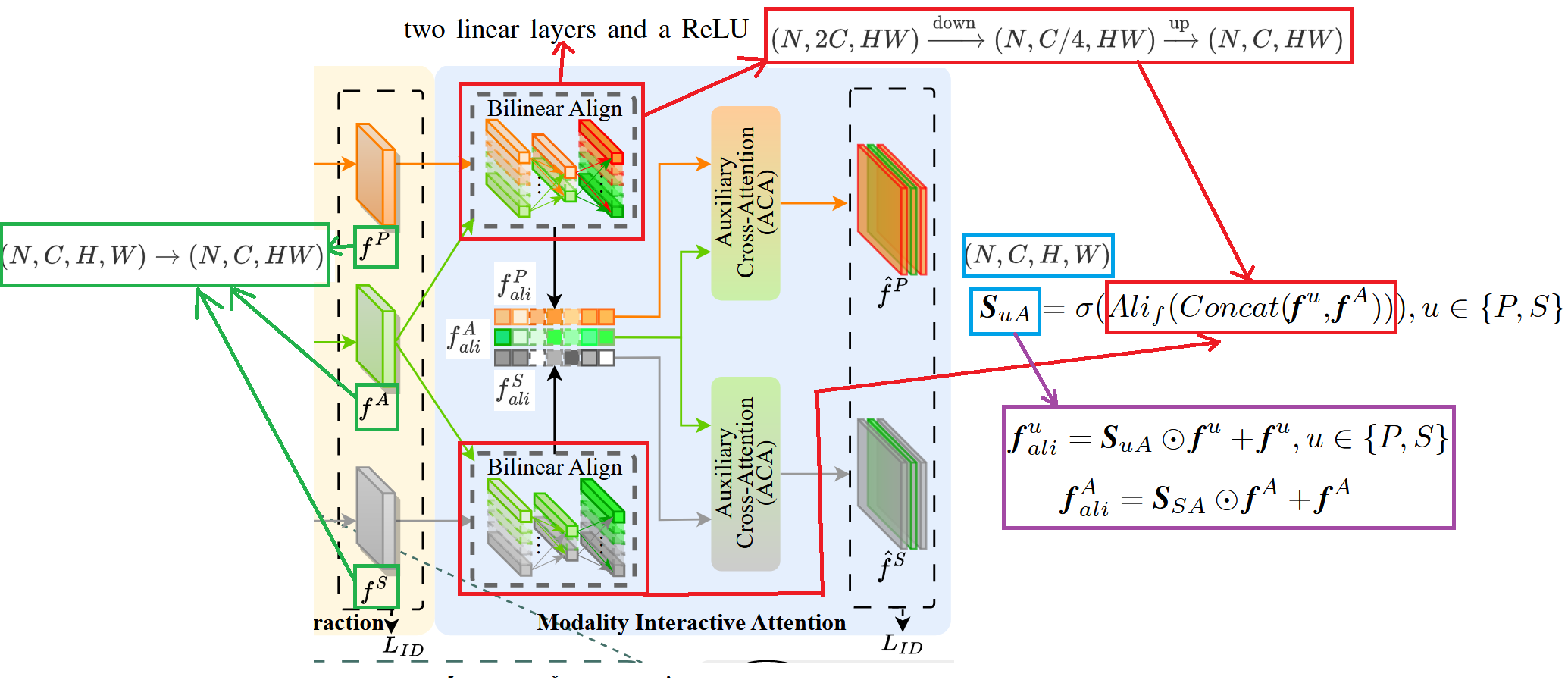
双线性对齐模块(BAM)如上图所示,其核心作用是利用辅助模态的特征图 去和另外两个模态的特征图 、 计算相似度权重 (其中 )。可以把 理解为一张“注意力打分图”:它刻画了在每个空间位置、每个通道上,当前模态特征与辅助模态特征的匹配程度,匹配高的位置会被赋予更大的权重,从而在后续对特征进行加权时突出更可靠、更一致的行人结构线索。具体计算时,先将 与目标模态的 在通道维进行拼接,然后送入双线性对齐单元建模两者的二阶交互关系,得到对齐后的响应,再通过 函数 将其归一化到 范围,形成相似度概率 ,用于对 做注意力加权增强并输出对齐特征。
双线性对齐具体步骤如上图所示,首先要先对张量进行 reshape。原来的 、 和 ,实际上都是 形状的张量。其中 表示批次大小, 表示通道数, 和 分别表示特征图的高和宽。首先把形状调整成 ,然后进行堆叠拼接,得到一个 在通道上拼接的结果,如上图的红框内所示,我以上方的红框内的 与 的为例,这两个特征图 reshape 后,都用一系列的长条表示,其中向屏幕内部延伸的长度可以抽象为 ,垂直方向的数量可以表示为通道数 ,两个特征图堆叠起来就是一共有 个长条 (上半部分 C 个橙色,下半部分 C 个绿色),之后进入一个线性层,把通道压缩到 ,目的是在不丢失关键信息的前提下先“降维压缩”两模态拼接后的通道表达,做一次轻量的瓶颈变换:因为拼接后通道数变成了 ,如果直接在高维空间做双线性交互,参数量和计算量都会很大,而且容易过拟合;因此先用第一层线性层把通道压到 ,相当于做特征筛选与信息蒸馏,保留最有助于两模态对齐的相关成分。然后再进入一个线性层,把通道还原回 ,目的是为了把压缩后的“对齐关系”重新映射回与原 backbone 特征一致的通道维度,方便后续与原特征进行融合/逐元素运算,并且输出的维度与后续模块(如相似度估计和注意力加权)保持匹配。
计算得到的 会再 reshape 回 的形状,以便与原始特征图 在空间位置与通道维上一一对应。随后按照对齐公式 对特征进行加权增强:其中 作为注意力权重,对与辅助模态更一致的区域赋予更高响应、抑制不一致或噪声区域,并通过残差项保留原始信息。最终得到的 和 就是经过 Auxiliary 引导对齐后的 Photo 和 Sketch 特征图,为后续 ACA 的跨注意力交互提供更“干净”、更可对齐的表示。
同时,为了让后续 ACA 做跨注意力交互时,辅助模态也能以“对齐后的、更干净的表示”参与双向匹配(例如把 作为 Key/Query 与 或 进行交互),论文也对辅助模态本身做了一次同样的加权残差增强,得到对齐后的辅助特征 。具体定义为用草图与辅助模态的相似度权重 去加权 :。
最终得到的结果就是这样的了,深浅表示对特征的关注程度,越深关注越强,越浅则越弱。至于为什么有的是虚线框,论文里没有解释,我查阅一些画图的资料,了解到虚线可能表示三种模态下的一些公共特征。
Auxilirary Cross-Attention Module (ACA)
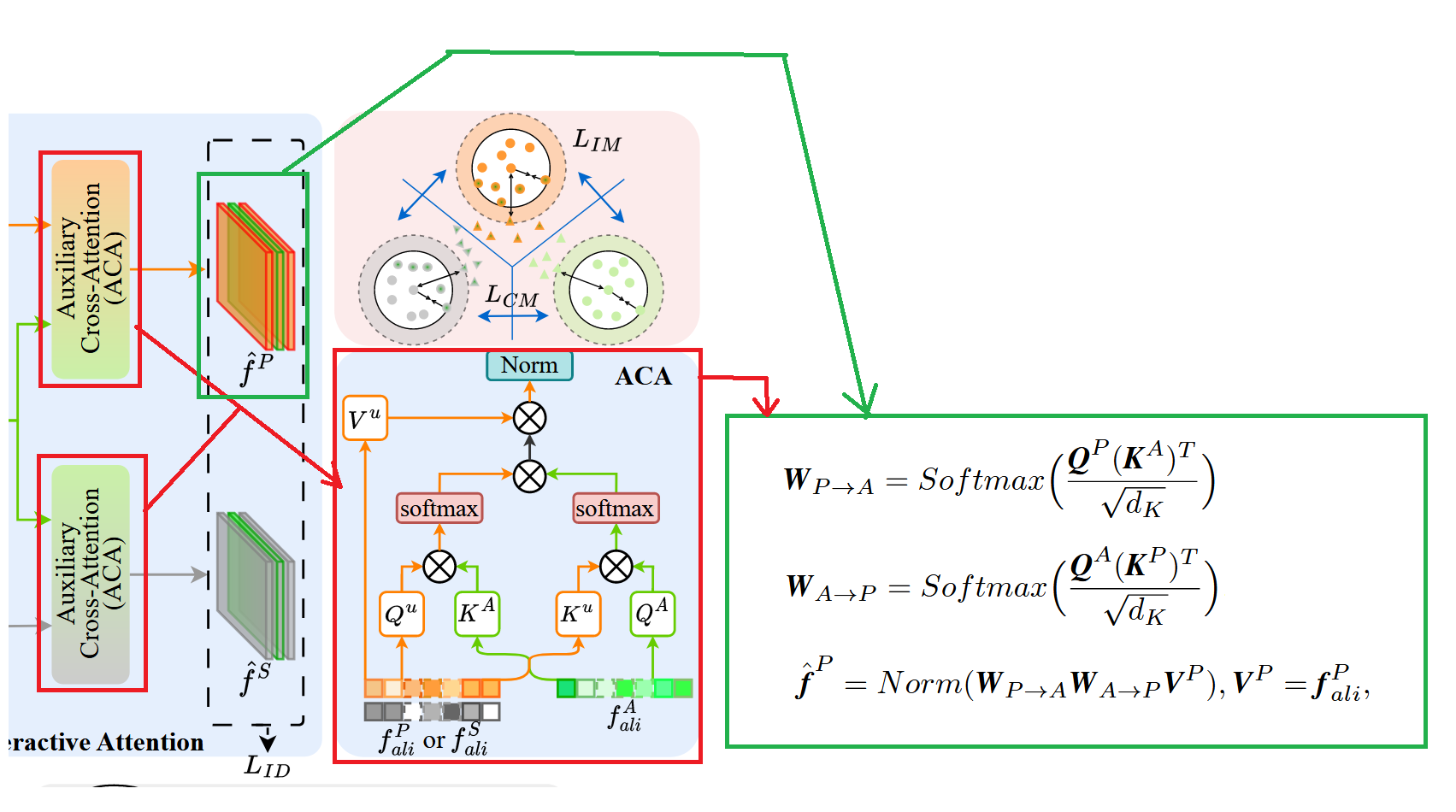
ACA 的目的不是再去“算一个相似度分数”,而是基于 BAM 得到的对齐特征,真正让三种模态之间发生信息交换与融合:论文强调它“利用辅助模态去引导模型学习模态共享表征的分布”,并且能在 photo 与 sketch 之间实现显著的信息交互与融合。
如上图所示,具体计算以 “photo 与 auxiliary 的交互” 为例:把 BAM 输出的对齐特征 和 分别视为 Query 与 Key(记作 和 ),然后用标准的缩放点积注意力得到从 photo 指向 auxiliary 的匹配权重 ,其中 是 Key 的通道维度。 同时再交换 Query与Key 得到反向的匹配权重。
有了双向权重后,论文用一个“往返一致”的方式来精炼 photo 特征:以 作为 Value,将 与 相乘后再去加权 ,最后做 LayerNorm,得到被辅助模态突出后的 photo 特征 这里可以理解为:先用 找到 photo 中哪些位置或模式能在 auxiliary 中找到对应,再用 把这种对应关系“映射回来”确认一致性,从而更稳健地强化两者共有的结构语义,抑制各自的噪声与不一致区域。
同理,把 与 做同样的双向 cross-attention,就能得到在 auxiliary 潜在表征引导下精炼后的 sketch 特征 。
Multi-Modality Collaborative Learning
多模态协同学习,这部分主要围绕两类损失来设计:一类是类别损失,用于保证三种模态的特征具备清晰的身份判别性;另一类是 circle loss 系列的度量学习损失,其中跨模态 circle loss 用来约束不同模态但同一身份的样本在特征空间中相互靠近、不同身份相互分离,从整体上实现模态间对齐;同时再引入模态内 circle loss,专门压缩同一模态内部同身份样本的分布、拉开不同身份距离,以缓解草图风格差异和照片视角/光照/背景变化带来的类内离散问题。两者配合,使模型同时完成模态间与模态内的对齐。
类别损失
如上图所示,类别(身份)损失用的是 ,目的是用“身份监督”把三种模态拉到同一个可分的身份空间里,让同一人的 Photo / Auxiliary / Sketch 学到一致的身份模式。论文把它写成两部分相加:,其中 表示三种模态经过共享 ResBlocks 输出的特征图集合, 表示经过 MIA 细粒度交互增强后的 Photo 与 Sketch 特征图集合,而 就是标准的交叉熵分类损失(用真实身份标签做 softmax 分类监督)。这样设计的直观含义是:一方面直接约束共享骨干提取到的三模态基础表征在身份层面对齐;另一方面也约束经过辅助模态引导交互后的增强表征仍然保持正确的身份判别性,避免注意力交互把特征“对齐”到错误的人或引入身份无关的偏移。
Circle Loss 损失
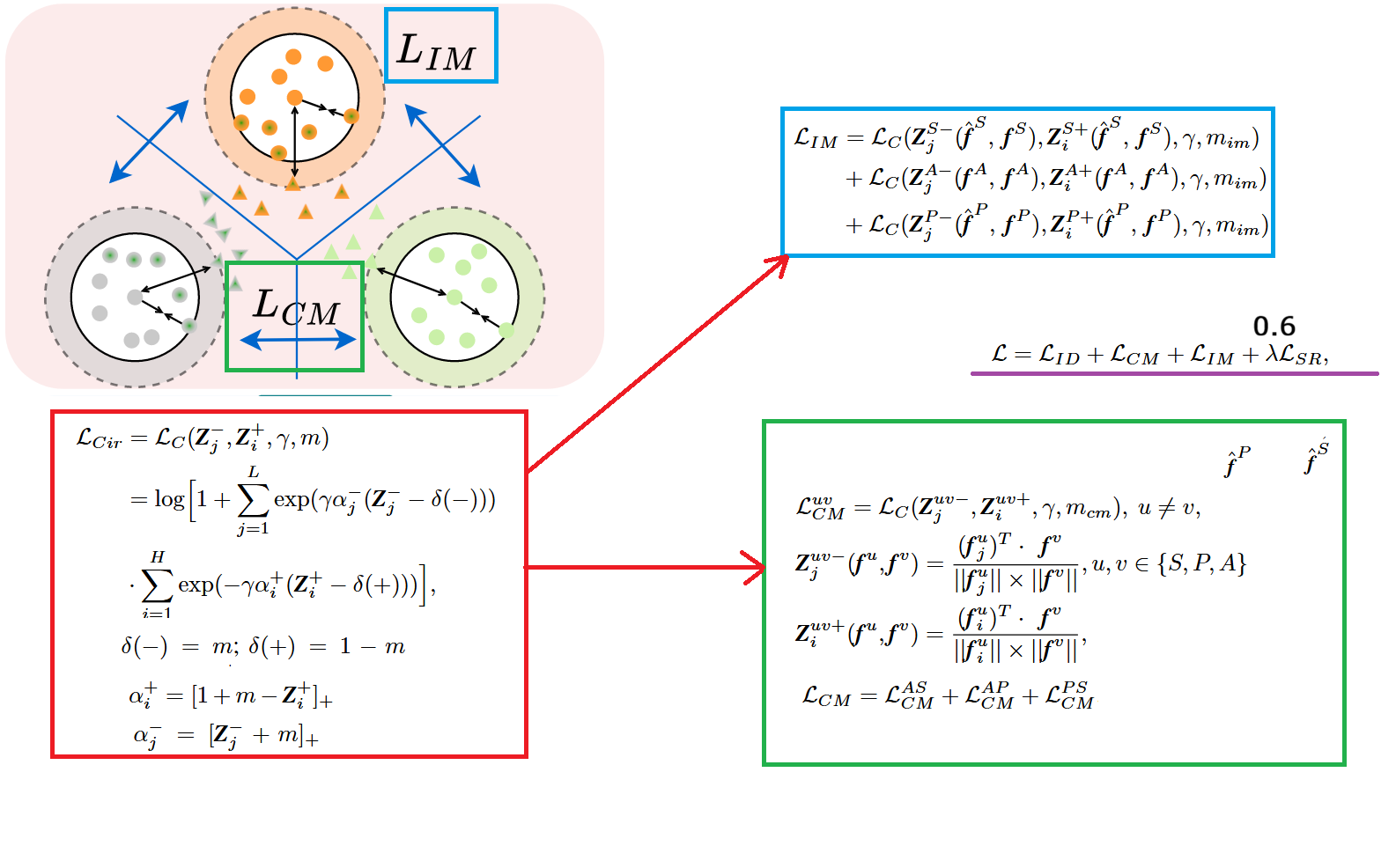
如上图所示,论文基于 2020 年提出的 circle loss,进行一波改进,适用于草图和图像,并设计了两个损失函数,一个是 ,这个是用于模态间的对齐;另一个是 这个是用于模态内的对齐。
论文用 circle loss 来做度量学习约束,而不是常见的 triplet loss,核心原因是:Sketch Re-ID 同时存在“跨模态差异巨大且每个身份样本极少”的问题,单纯用 triplet 往往只在少量三元组上做局部约束,容易出现优化不稳定、对难样本依赖强、以及只顾跨模态而忽略模态内分布的现象;circle loss 则以“成对相似度优化”的统一形式,把一个 batch 中的多对正负样本一起纳入优化,并通过自适应权重 更强调那些“更难”的正负对,从而更适合在有限样本下学习更稳健的度量空间。
我先说一下我对原始 circle loss 的一个理解,原始公式如上图的红框内所示。它把“相似度”当作优化对象:对同一身份形成的正样本对,相似度记为 (希望它尽可能大);对不同身份形成的负样本对,相似度记为 (希望它尽可能小)。因此它的核心就是同时做两件事:一边把所有 往 1 拉(拉近同类),一边把所有 往 0 甚至更小拉(推远异类)。它把正对和负对分别放进指数函数里做加权求和:正对那一项的指数部分大致是 ,当某个正对相似度 还不够大、低于期望阈值 时,括号是负的,指数项就会变大,对损失贡献变大,从而反向传播会强力推动这个正对去变得更相似;反过来如果 已经很大,超过 ,这项贡献就变小,说明“容易正样本”不会再被过度优化。负对那一项的指数部分则是 ,当某个负对相似度 偏大、超过阈值 时,这项会迅速变大,损失会更关注这些“难负样本”,从而推动它们的相似度下降;如果负对本来就很小(已经被分开),它的贡献就会被自动压低。这里的 、 由间隔 控制,相当于给正负对各自设定一个“达标线”,要求正对相似度尽量超过 ,负对相似度尽量低于 ; 是尺度系数,用来控制优化的“力度/陡峭程度”。而最关键的自适应权重就是 和 :它会让相似度不理想的正对( 小)和最容易混淆的负对( 大)获得更大的权重,从而把训练重点自然转移到“难样本对”上,这就是 circle loss 同时实现“拉近同类、推远异类”且更稳定的原因。
在此基础上,论文把 circle loss 的“成对相似度优化”思想进一步推广到三模态场景,并针对草图 Re-ID 的两个核心矛盾分别做了对应设计。首先是模态间对齐的 :它不再只在同一模态里构造正负对,而是直接在不同模态之间计算相似度来构造正负对,也就是把 和 变成跨模态的余弦相似度 、(),并对 、、 三组模态两两施加 circle loss 约束后相加。这样做的直观目的就是:同一身份的 sketch、photo、auxiliary 在特征空间里要彼此靠近,不同身份要分开;而且因为 auxiliary 处在“类草图”的中间态,它同时参与 和 的对齐,会在优化过程中起到桥梁作用,间接降低 的对齐难度。具体如上图里的绿色方框里的公式所示。
但如果只用 ,模型往往会把优化重心放在“跨模态差异”上,导致每个模态内部同一身份的分布仍然可能很散(比如同一个人不同摄像头的 photo 仍相距很远,或者不同画师的 sketch 风格差异仍很大),从而学到次优的潜在空间。因此论文又加了模态内对齐的 :它仍然使用 circle loss 的形式,但构造正负对时是在同一模态内部做约束,并且为了在样本少的情况下制造更有力度的监督,它把同一模态里交互前的特征 与交互后的特征 配对来构造正样本对(同一身份应当一致),同时选取最容易混淆的异身份配对作为负样本对。这样一来, 负责把不同模态拉到同一度量空间、完成模态间对齐, 负责在各自模态内部压缩类内离散、拉开类间间隔;两者配合,就能同时缓解“跨模态鸿沟”和“模态内差异大”这两个问题。具体如上图里的蓝色方框里的公式所示。
在实验的具体细节里,各参数的设置为 ,,。
总的损失函数就是上述四个损失函数之和,即 ,其中 。
3. 实验
数据集配置
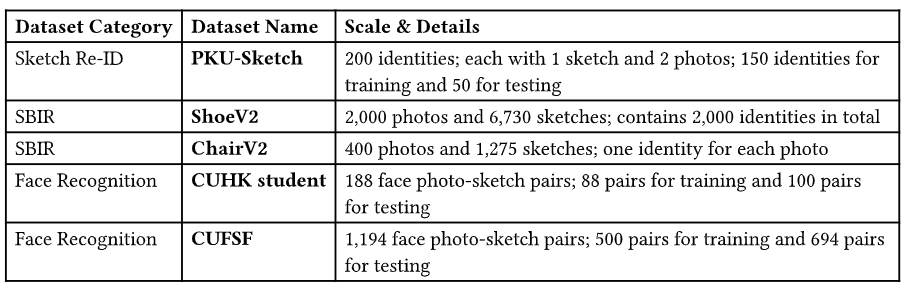
如上图,论文用到了如上 5 个数据集。
消融实验
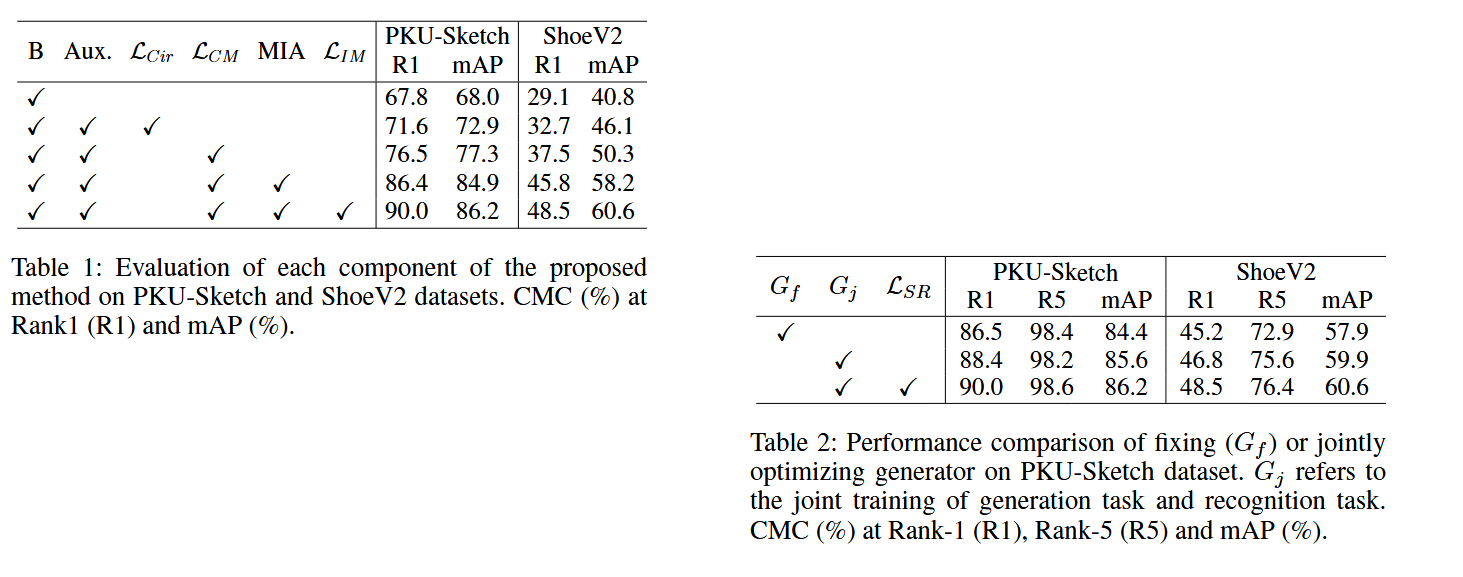
如上表1表示在 PKU-Sketch 和 ShoeV2 数据集上的进行消融实验,其中 B 表示 Baseline。论文说明这里的 Baseline 是“只用 identity loss 训练的 ResNet-50”;Aux. 表示是否引入辅助模态。 表示原始的 circle loss,后面的就是论文设计的损失函数和模块,可以发现,使用论文所提出的完整的模型和损失函数时,所有指标最高。
如上表2是为了验证 DAG 模块是否参与联合训练更新对整个模型的影响, 表示固定参数, 表示参数参与训练优化,这里就是指的是那个卷积核的参数。 指的就是那个风格细化损失。可以发现,当使用 损失函数在训练时优化 DAG 模块的参数才能使得模型效果最好,指标最高。
对比实验
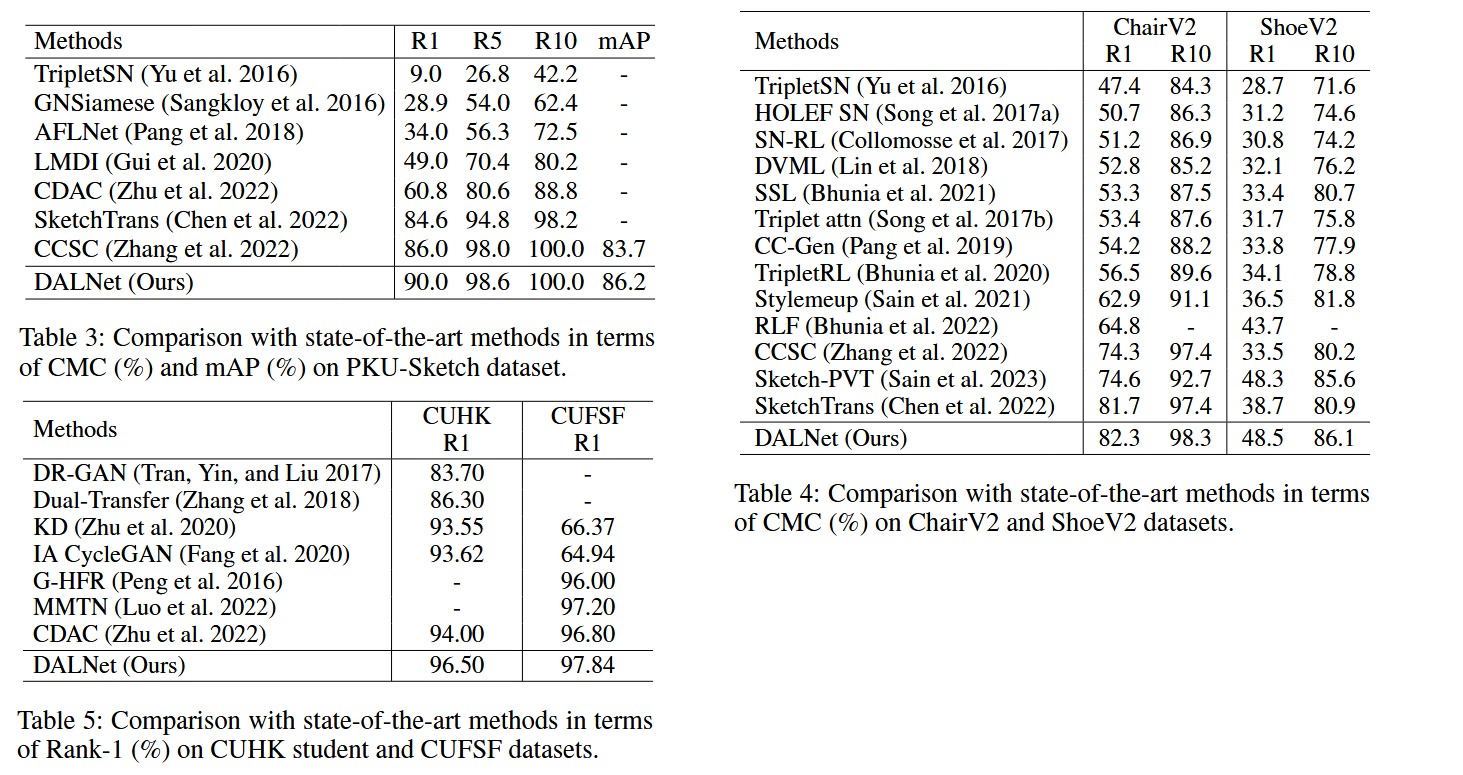
如上表3~表5是在不同数据集上与当前的 SoTA 模型进行对比,可以看到不管是在哪个数据集上,本文提出的模型各个指标最高。
可视化展示
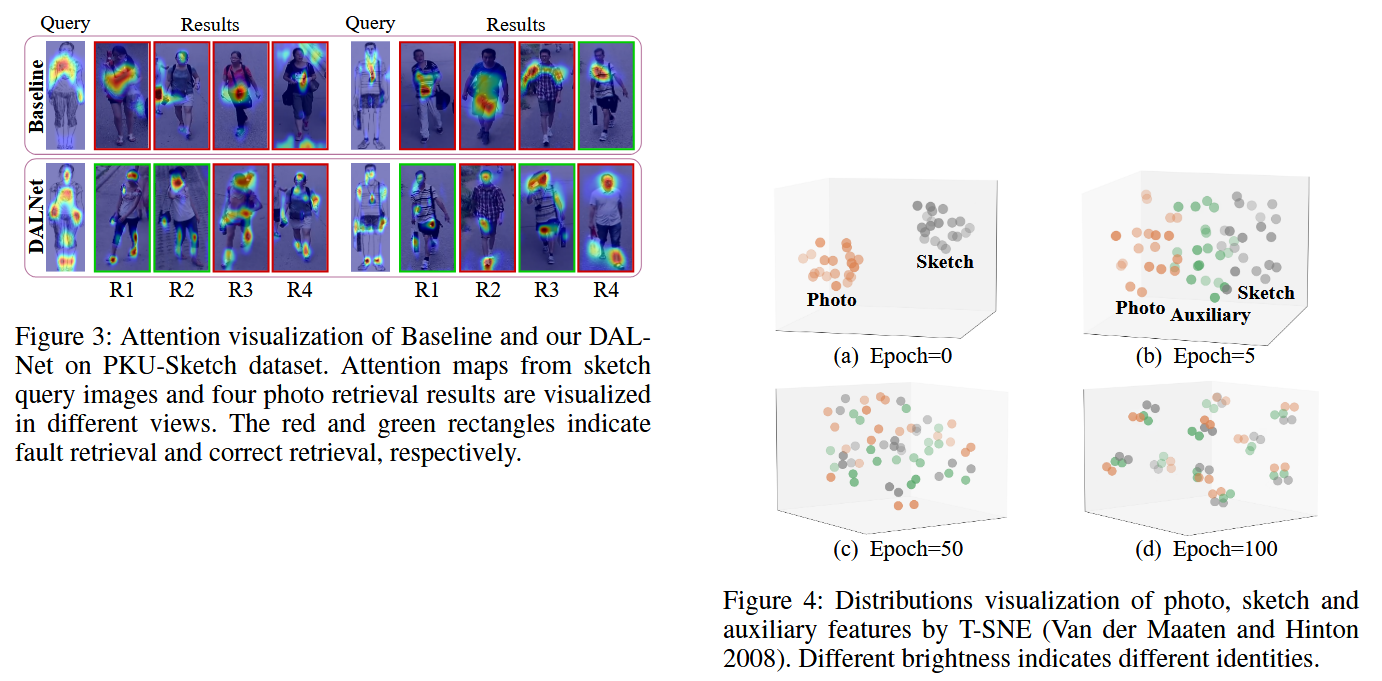
图3是在做“注意力可视化对比”。论文用 XGrad-CAM 把两条不同视角的草图 query,以及各自 top-4 的检索照片结果的注意力热力图画出来,并用红框和绿框分别标记错误检索和正确检索。 结论很直观:Baseline 的注意力容易忽视草图与照片之间真正相关的区域,尤其在场景和姿态变化时会被一些相似局部干扰;而 DALNet 能同时关注到更“跨模态共享”的人体线索(比如脸部关键区域、衣服纹理、包、胸牌等),所以正确检索(绿框)更多。
图4是在做“特征分布对齐过程的可视化”。论文随机选了 PKU-Sketch 的 10 个身份,用 t-SNE 把三种模态的特征分布在训练不同 epoch 下画出来(亮度区分不同身份)。 现象是:epoch=0 时 photo(橙)和 sketch(灰)分布差异很大;训练推进后 auxiliary(绿)像“桥”一样把两者连起来;到 epoch=50 时 photo 和 sketch 逐渐收敛,同时类内更紧、类间更开;最终 epoch=100 时 auxiliary 特征会聚到各自身份中心,说明模型学到了更强的身份判别性,并把三模态分布对齐起来。
结论
本文针对草图行人检索中跨模态鸿沟大与模态内变化剧烈的问题,提出 DALNet:先由 DAG 从真实照片生成“类草图”辅助模态作为桥梁,再用三流共享骨干提取特征,并通过 MIA 在辅助模态引导下实现细粒度跨模态交互融合,最后用分类损失与改进的 circle loss(同时包含跨模态与模态内)联合优化,实现模态间与模态内的同步对齐。
创新点在于引入可训练的动态辅助模态生成与风格细化约束来缩小模态差异,并设计“辅助引导的交互注意力和跨模态与模态内的 circle loss”这一整套协同学习机制,使特征分布对齐更稳定、检索性能更强。