论文的题目为:Modalities collaboration and granularities interaction for fine–grained sketch-based image retrieval 。
可以翻译为:细粒度草图图像检索中的模态协同与粒度交互。
这篇论文发表在 Pattern Recognition 2026 上。

1. 动机
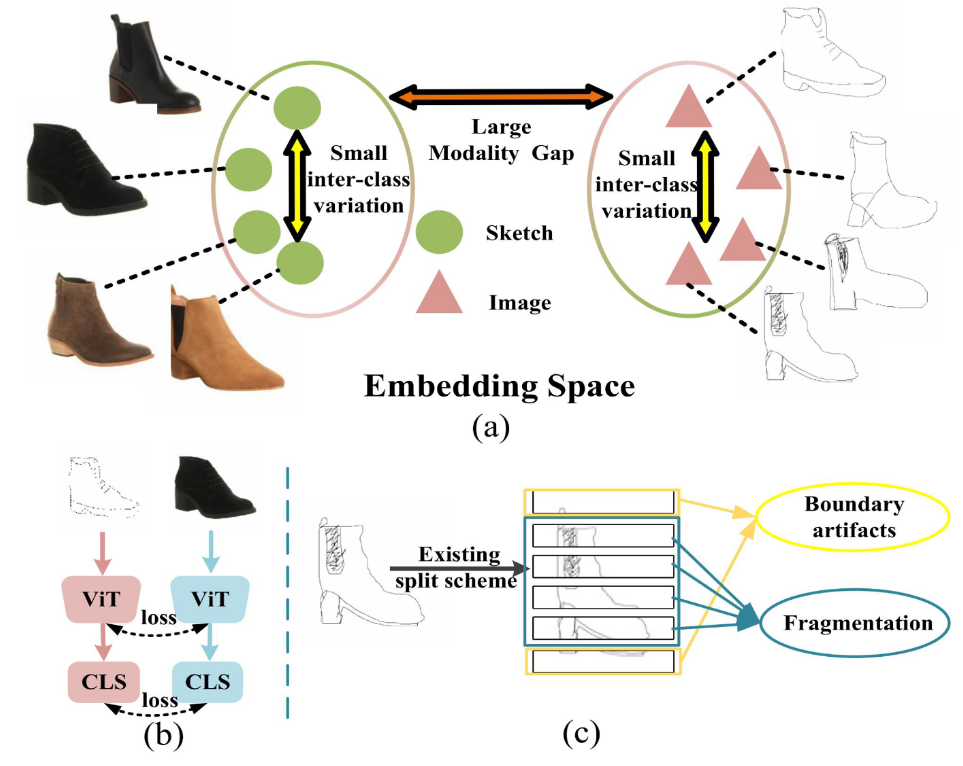
如上图,论文动机就两个:
-
如图 a,现有方法只关注单模态特征提取,忽略了草图(结构轮廓)和照片(纹理颜色)之间的互补性,且同实例跨模态差异大、不同实例单模态内差异小的特点使直接对齐困难。草图和真实图像之间的互补信息未充分利用。
-
如图 c,固定大小的块划分会产生边界噪声并割裂完整特征,同时缺少跨粒度特征交互,无法利用多尺度上下文信息增强判别性。
整篇论文就是为了解决这两个问题的。
2. 方法
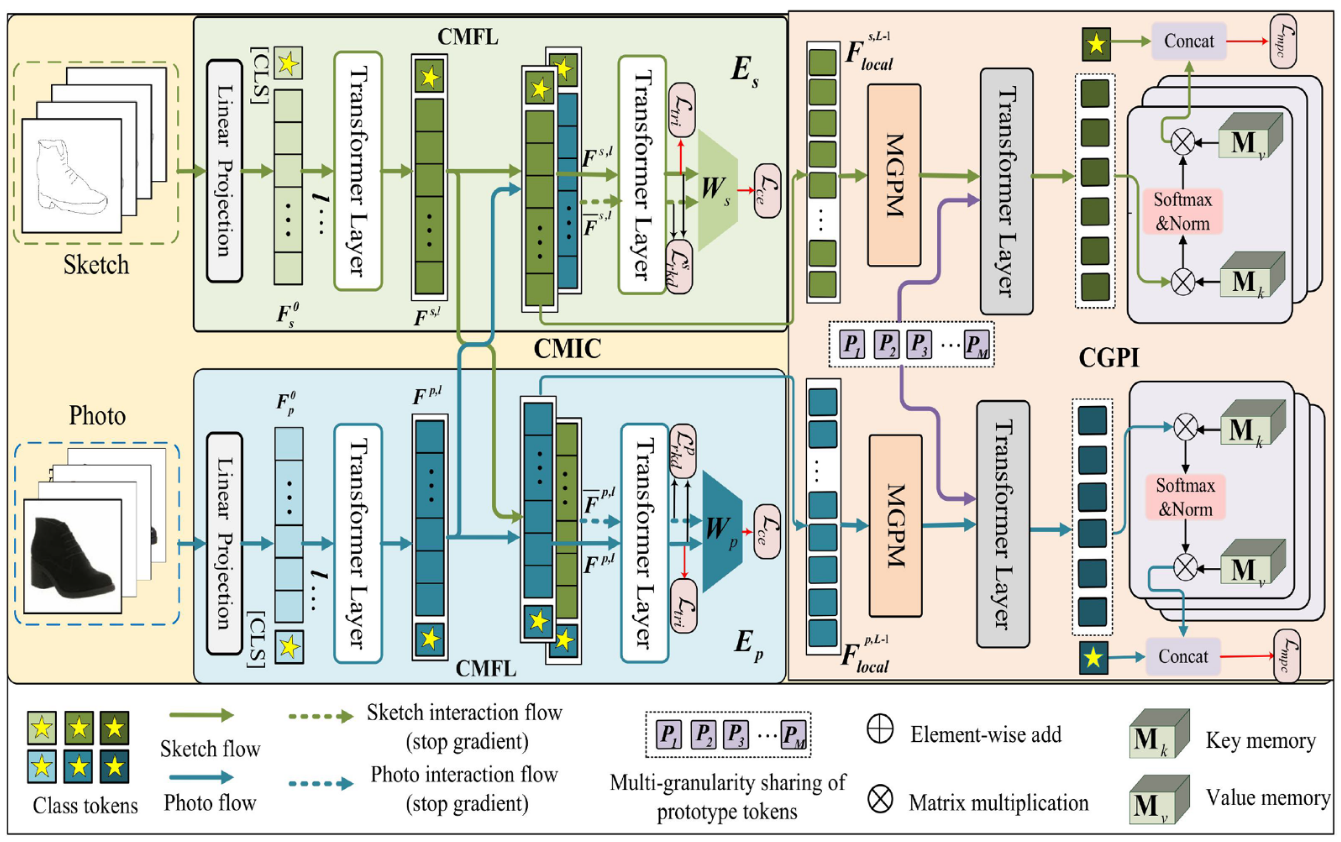
上面是论文提出的方法总体框架图,框架名称简称为 MCGI,大致可以分为 3 个大模块:CMFL、CMIC和 CGPI。其中 CGPI 又分为三个小模块:MGPM、CGII 和 MGPC。
CMFL (Cross-Modality Feature Learning)
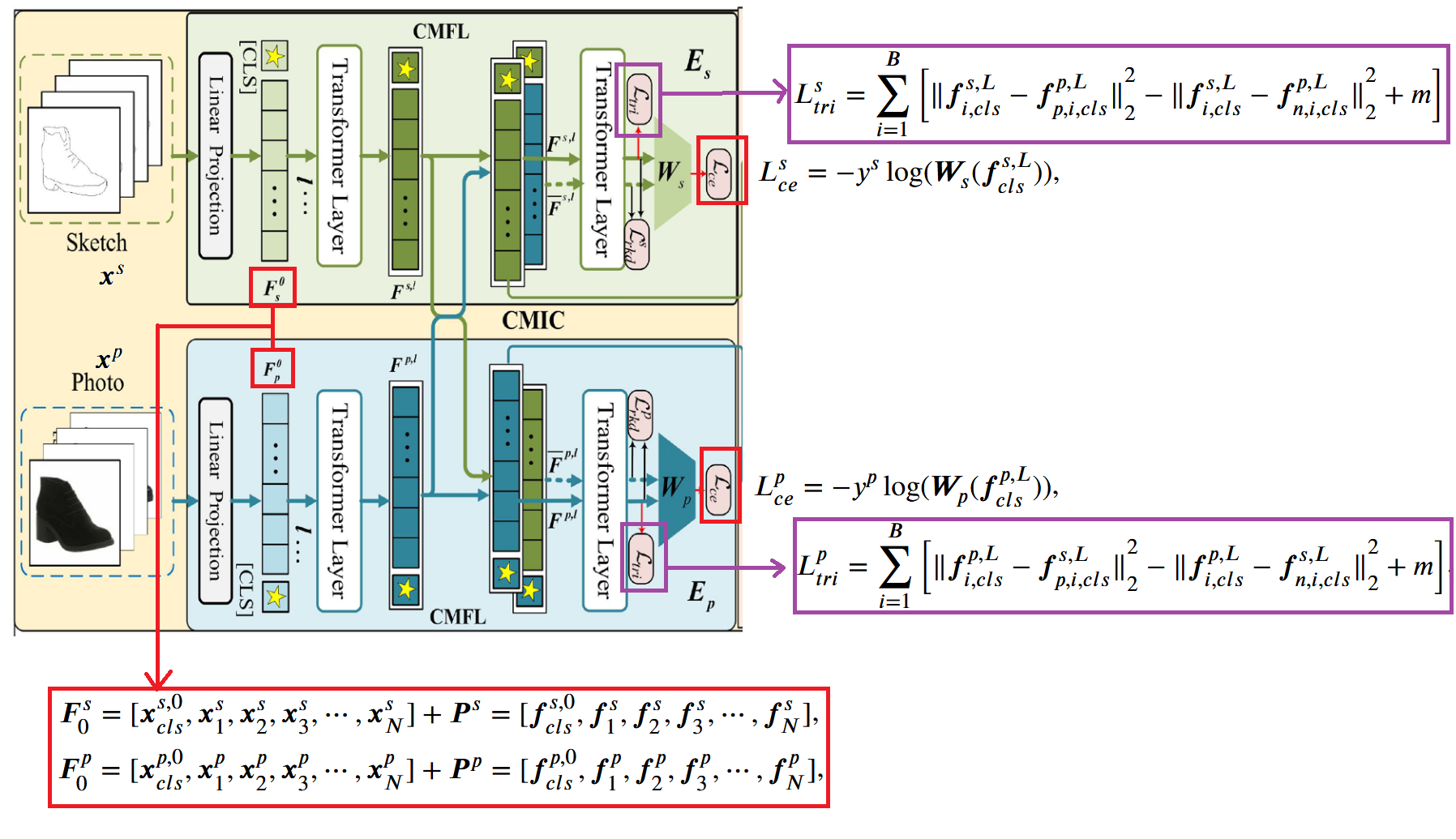
跨模态特征学习模块,这个不是论文的创新点,可以说这就是一个基线模块,这部分论文用的 ViT-B/16 编码器,草图或图像切割成 token 加上位置编码和 [CLS] token 后分别进入编码器的 L 个层(12 层),然后输出的 和 这两个 [CLS] token (前者表示草图的,后者表示真实图像的),然后把这两个 [CLS] token 分别放入 和 这两个分类器,对分类结果计算交叉熵损失 和 。同时进行基本的跨模态对齐,论文使用的是三元组损失并且进行互对齐,计算得到的三元组损失分别为 和 ,具体公式如下图所示:
CMIC (Cross-Modality Information Compensation)
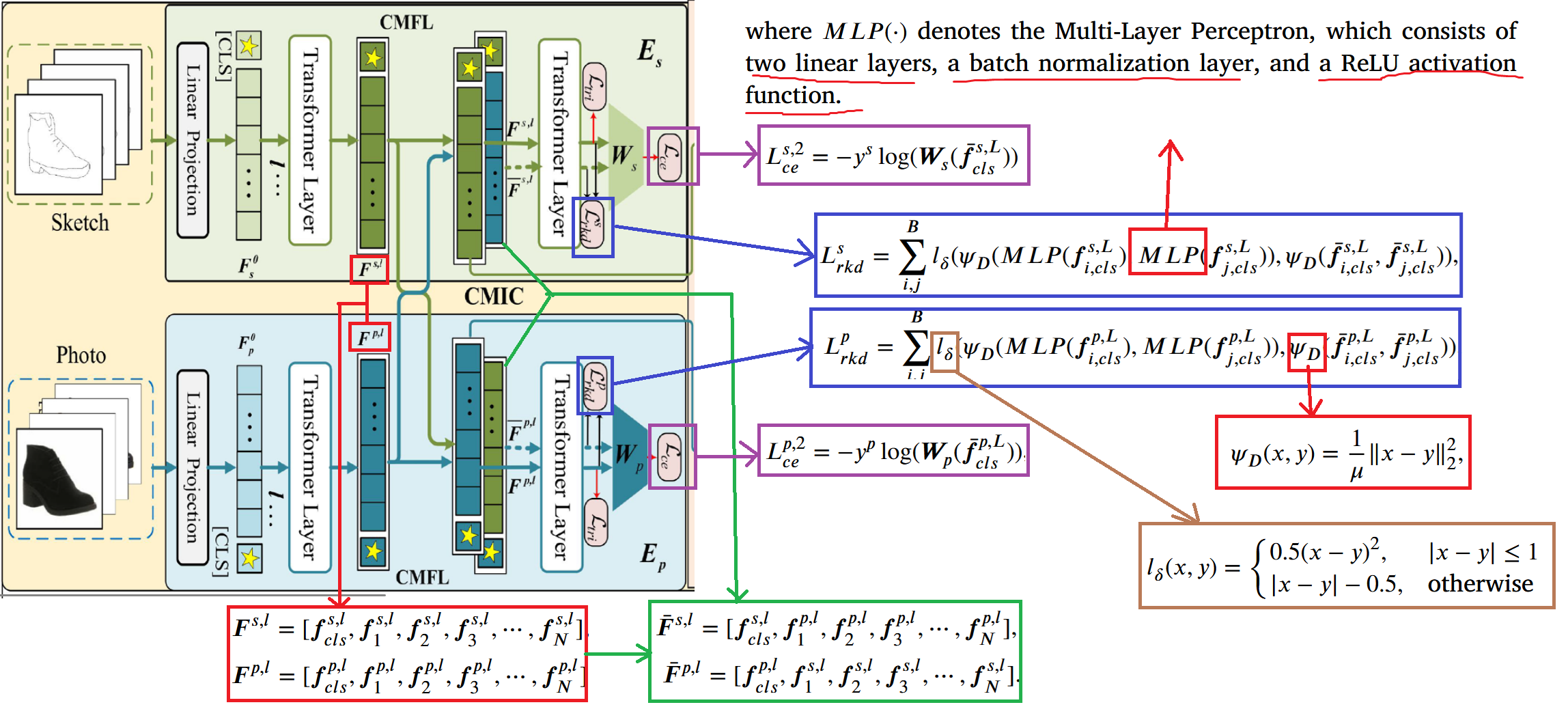
跨模态信息补偿模块,这是论文提出的第一个创新点,用来解决动机里面的问题 1。方法是对第 l 层(论文取 l = 11)的输出 token 进行交换,交换方法时保留 [CLS] token 不交换,只交换 N 个 patch token,交换前的 token 集合表示为 和 (前者表示草图的,后者表示真实图像的),交换后的 token 集合表示为 和 。 然后交换完的 token 集合通过剩下的 层得到输出,分别取两侧的 [CLS] token,分别为的 和 ,用这两个 token 再去如法炮制按照 CMFL 那样计算交叉熵损失得到 和 。
但是有一个问题,我们在训练阶段虽然知道草图和图像是一一配对的,但是在推理阶段不知道配对关系,因此论文设计了一个关系知识蒸馏,把 CMFL 模块输出的两个 [CLS] token: 和 分别传入两个 MLP 来模拟交换 token 后的输出,并设计损失函数 和 进行蒸馏,具体公式如下, 表示距离函数, 表示距离的归一化因子, 表示 Huber 损失函数。
CGPI (Cross-Granularity Prototype Interaction)
跨粒度原型交互模块,这是论文的第 2 个创新点,这个就是来解决动机里的问题 2 的。该模块又分为以下三个小模块。
MGPM (Multi-Granularity Prototype Learning Module)
多粒度原型学习模块。该模块论文中简称有两种,分别是 MGPM 和 MGPL。论文的框架图中写的是 MGPM,后面的文字介绍中写的 MGPL,为了统一且便于讲解,我这里使用 MGPM 这种简写方式。
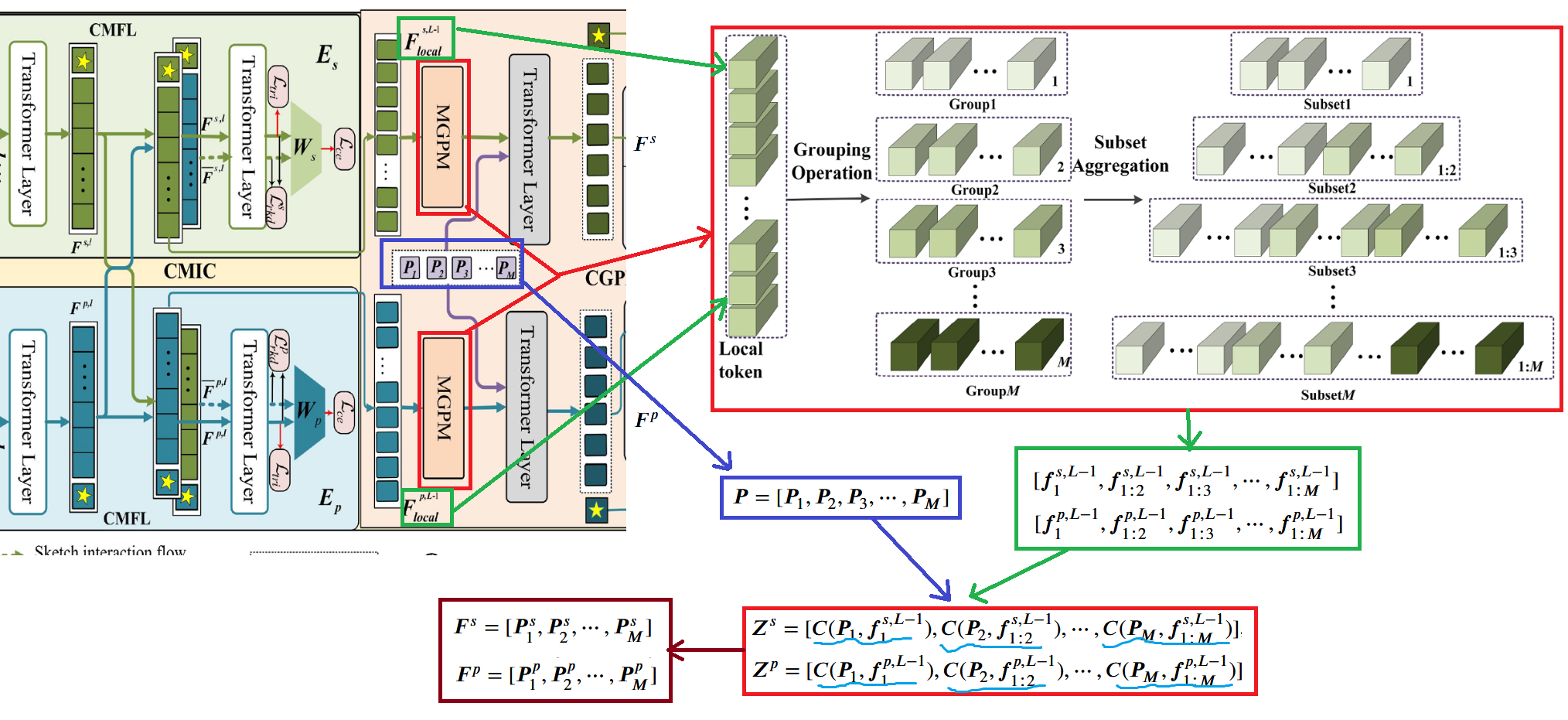
该模块取第 L - 1 层的 patch token 输出 (不含 [CLS] token),草图和真实图像的输出分别为 和 ,然后分别平均分成 组 (论文里取 ),每组有 个 token,然后,逐步聚合这些组形成不同粒度的特征序列 和 ,其中 表示前 个组的 token 拼接在一起。
为了增强这些多粒度特征的判别性,论文引入可学习的多粒度共享原型 ,将每个粒度的原型与对应的 local tokens 拼接: 和 ,其中 表示拼接操作。这些原型的作用类似于 [CLS] token,每个原型 负责聚合第 个粒度的全局特征表示。
然后把 和 分别送入第 层 Transfomer Encoder 得到 和 ,具体详细图解流程与公式如下图所示。
CGII (Cross-granularity information interaction)
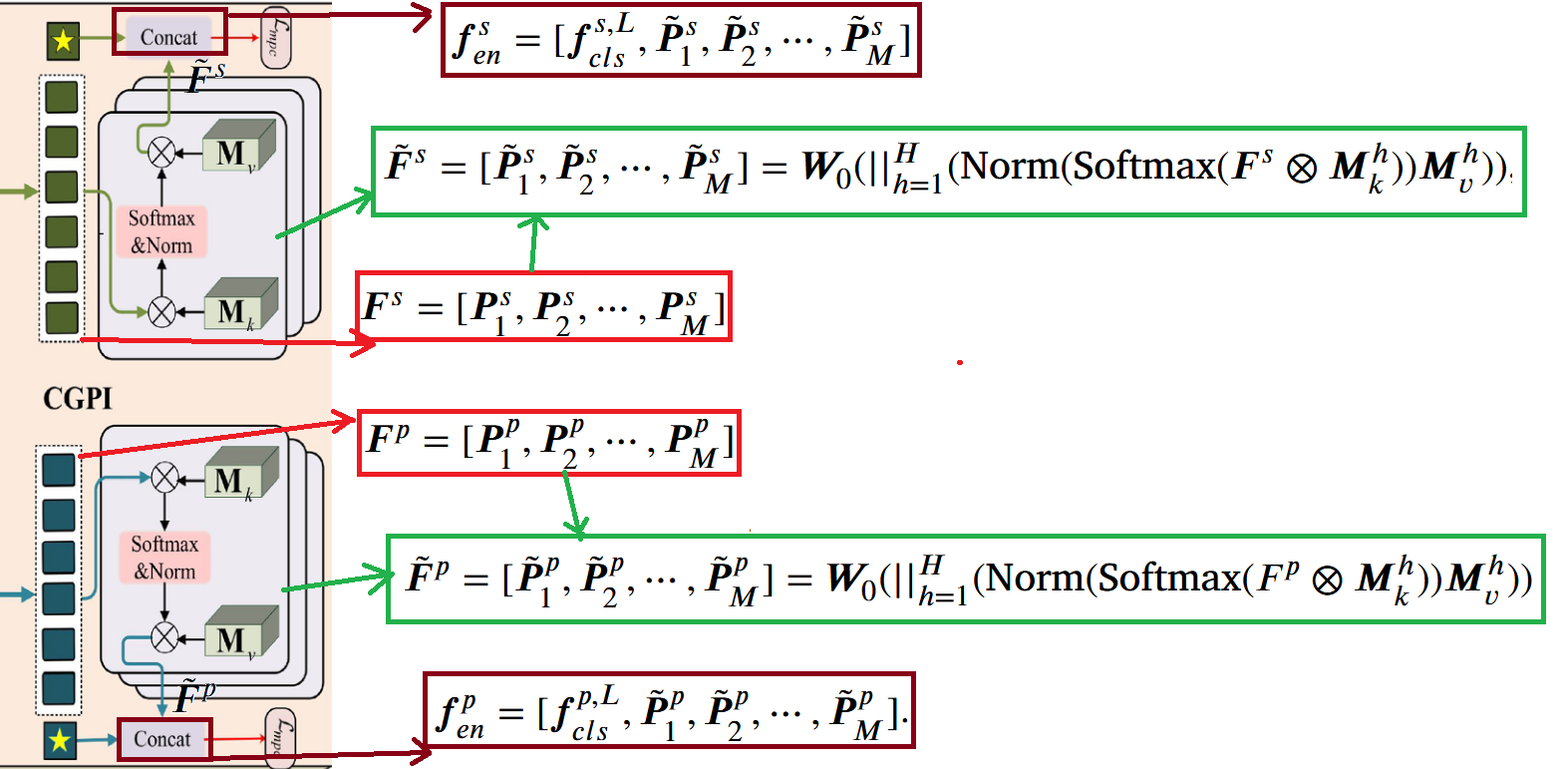
跨粒度信息交互模块,这个模块是用来继续处理上一个模块的输出的,该模块通过引入两个外部记忆单元 和 作为 Key 和 Value,将多粒度原型特征 和 作为 Query,计算跨粒度的注意力权重来捕获不同粒度之间的上下文关联。通过多头注意力机制聚合不同粒度的信息,输出增强后的多粒度特征 和 ,最后与全局 [CLS] token 拼接得到完整的增强特征集 和 。具体流程如下所示:
MGPC (Multi-Granularity Prototype-aware Contrastive Loss)
多粒度原型感知对比损失模块,该模块使用上一个模块输出的 和 ,计算对比损失 来进一步对齐跨模态的多粒度特征表示。该损失通过增加正样本对(配对的草图-照片)在多粒度特征空间中的相似度,同时减小负样本对的相似度,促进草图和照片在多粒度层面的特征对齐。具体流程和公式如下:
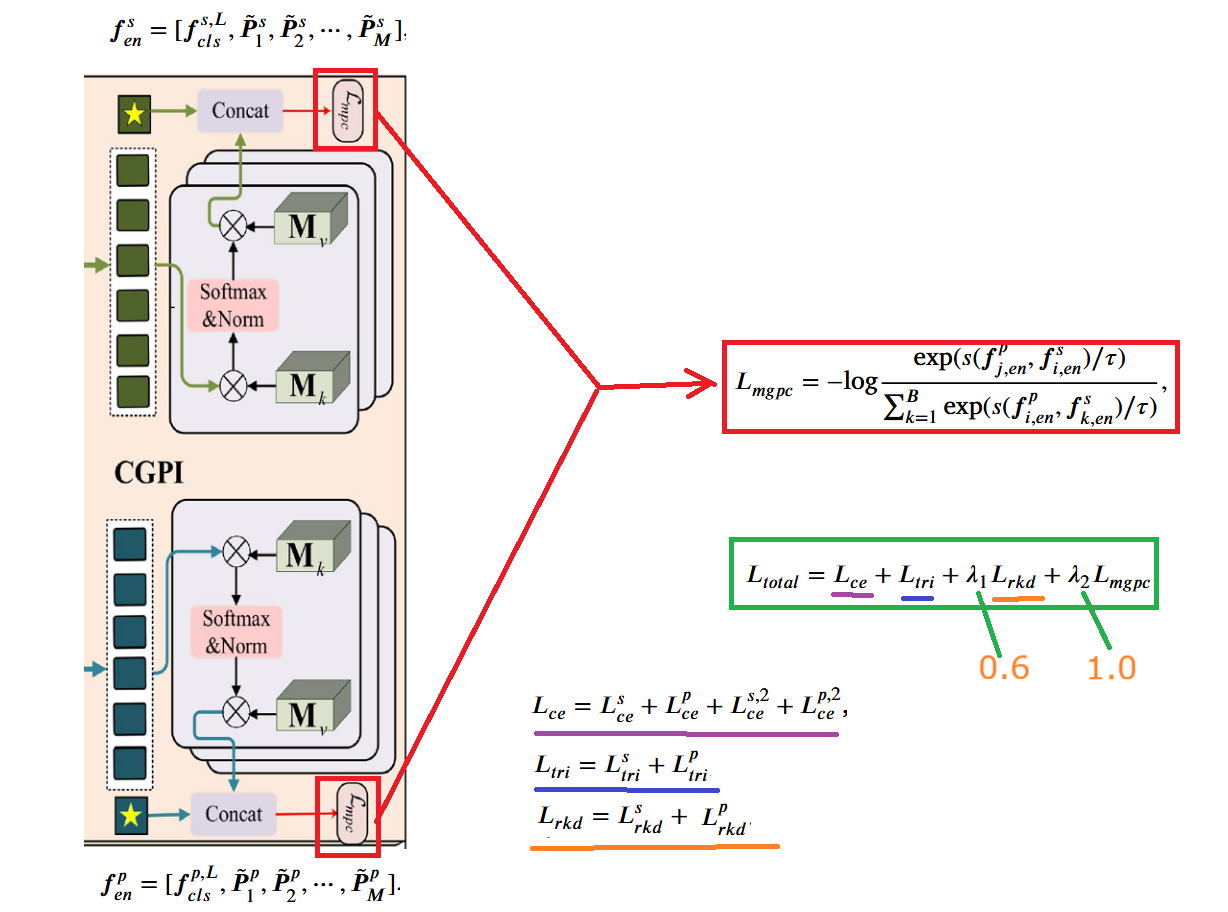
总体损失,便是上述所有损失加权求和,其中取 ,。这两个参数调优在后面实验会进行探讨。
3. 实验
数据集设置
实验设置如下,用到了四个数据集:
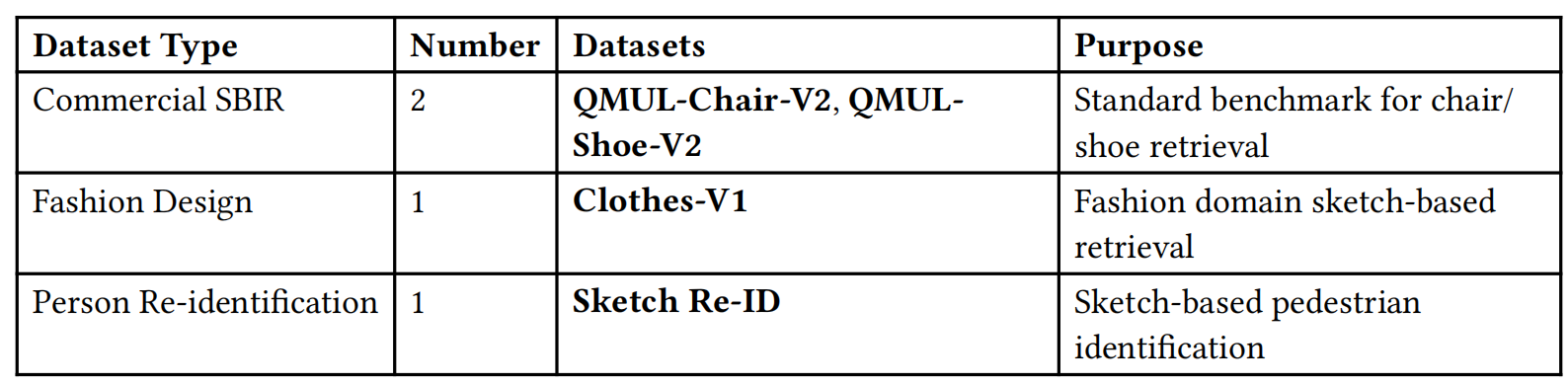
分别是椅子数据集、鞋子数据集、衣服数据集和行人数据集。

与当前先进的方法对比
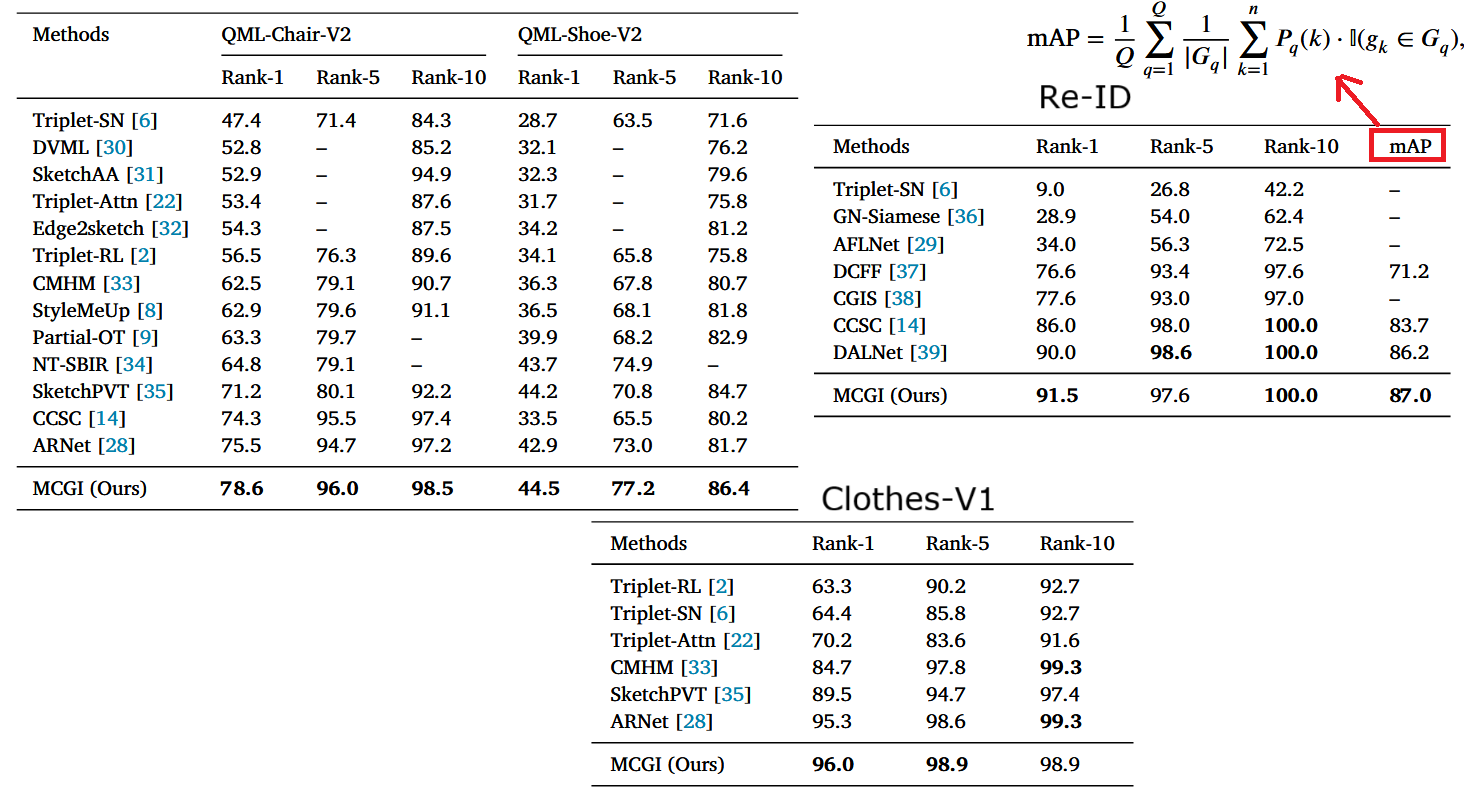
上图三个表展示了在不同数据集下,与当前先进的方法进行的对比,可以发现改论文的模型总体效果更好,尤其是在椅子和鞋子数据集上,在所有指标上都具有提升。
消融实验
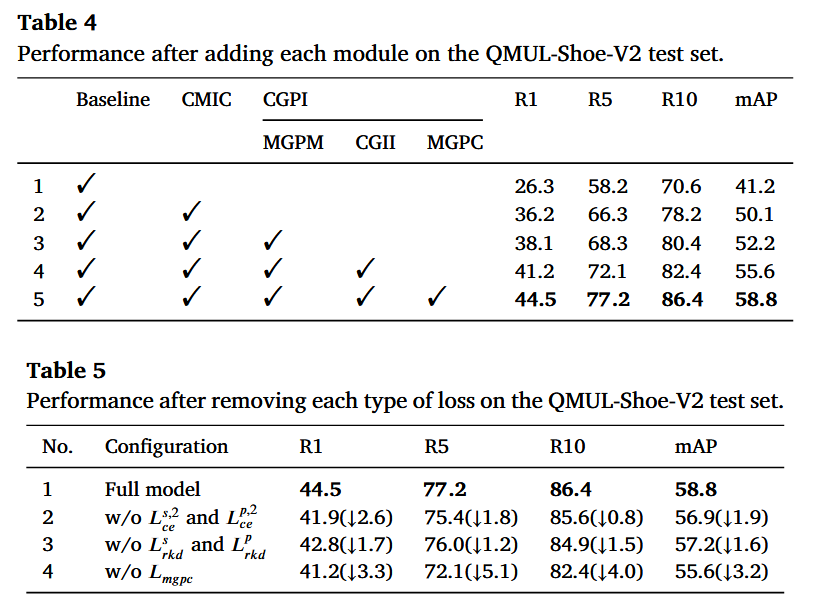
如上图,第一个表是在鞋子数据集上进行的消融实验分析,探讨论文提出的四个创新性的模块的作用,可以发现只有所有模块都使用时,指标是最高的,这说明每个模块都不可或缺。
第二个表是对各损失函数进行消融分析,也是在鞋子数据集上进行实验分析,可以发现,移除任意一种损失函数都会导致模型性能出现不同程度的下降。这些结果验证了所提出的每个损失函数对模型整体性能的有效贡献。
超参数分析
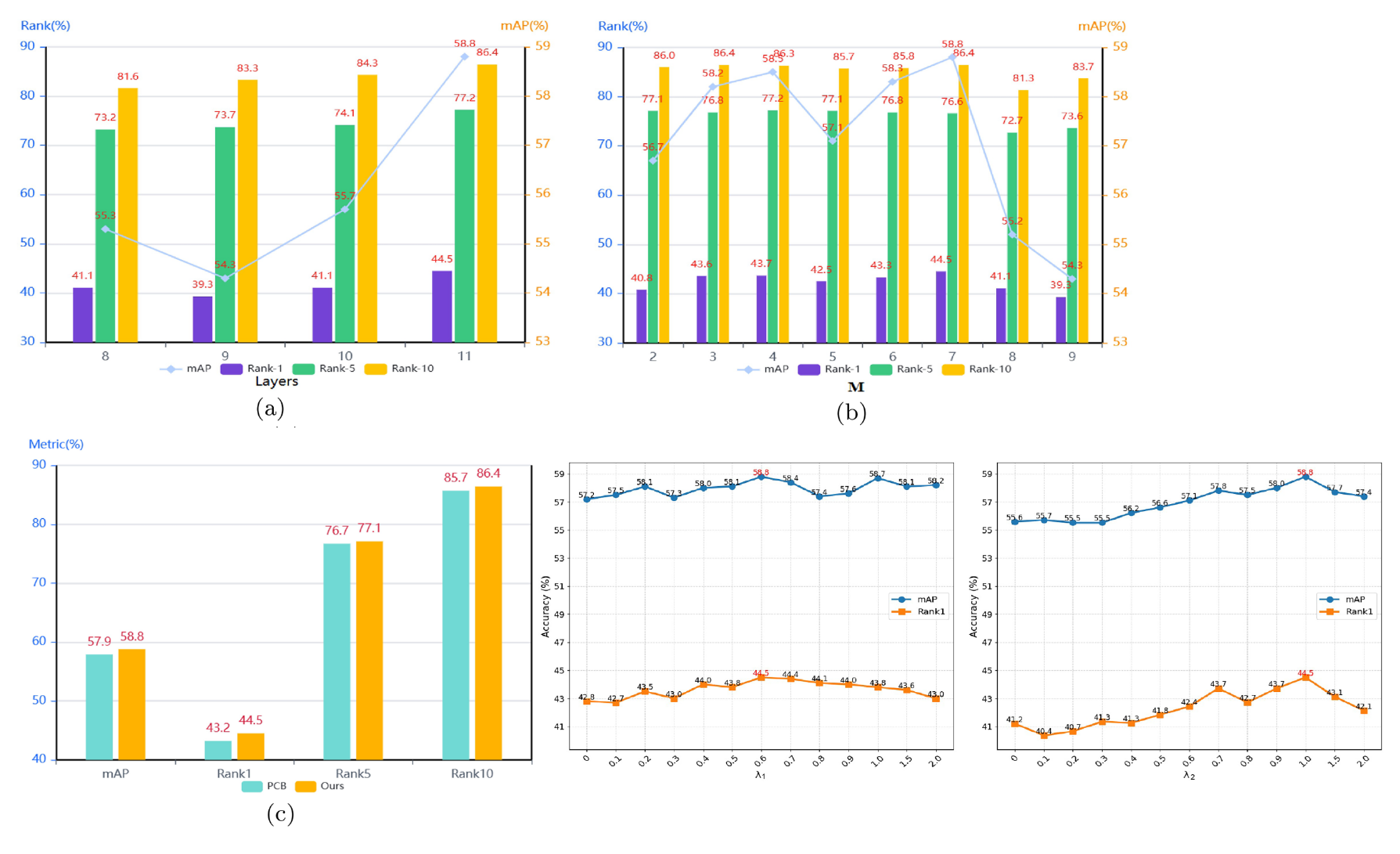
如上图所示,(a) 图展示了在不同层进行 token 交换对模型性能的影响。实验结果表明,随着层数 的增加,各准确率和 mAP 均呈现出逐步上升的趋势,并在 时达到峰值,因此论文 取 。
(b) 图展示了多粒度数量 (也就是前面的分组数量) 对模型性能的影响。实验结果显示,当 取 时,各项指标整体最好,且 mAP 最高。
(c) 图对比了本文提出的 MGPM 模块与传统固定块划分策略(PCB)的性能差异。实验结果表明,MGPL 在所有评价指标上均显著优于 PCB,验证了层次化粒度划分策略的有效性,因此论文采用 MGPM 作为多粒度特征学习方法。
后面两个折线图分别是来实验 与 的取值对实验的影响的,可以发现 , 时效果最好。
实验展示

上图展示了该论文提出的方法在四个数据集上的检索结果可视化,其中绿色方框表示检索正确的图像,红色方框表示检索错误的图像。方法能够将正确的目标图像排在更靠前的位置。这一改进在椅子、鞋子、服装和行人等不同类型的数据集上均有体现,证明了该论文框架具有良好的泛化能力。
4. 总结
MCGI 框架通过利用跨模态互补信息和跨粒度上下文关联来解决细粒度草图图像检索问题,从而弥合模态差异并增强特征判别性。
跨模态信息补偿(CMIC)模块通过 token 交换和知识蒸馏整合草图和照片的互补信息,以学习模态鲁棒的特征表示。
跨粒度原型交互(CGPI)模块分层提取多粒度特征并建模其上下文交互,以捕获判别性的细粒度信息。
在四个基准数据集上的大量实验证明了最先进的性能,在 QMUL-Chair-V2 上达到 78.6% 的 Rank-1 准确率,在 QMUL-Shoe-V2 上达到 44.5%,在 Clothes-V1 上达到 96.0%,在 Sketch Re-ID 上达到 91.5%。
消融研究验证了各个组件的有效性,其中 CMIC 提高了模态鲁棒性,CGPI 通过分层特征学习和跨粒度交互增强了细粒度判别性。