The paper is titled: Modalities collaboration and granularities interaction for fine-grained sketch-based image retrieval.
This paper was published in Pattern Recognition 2026.

1. Motivation
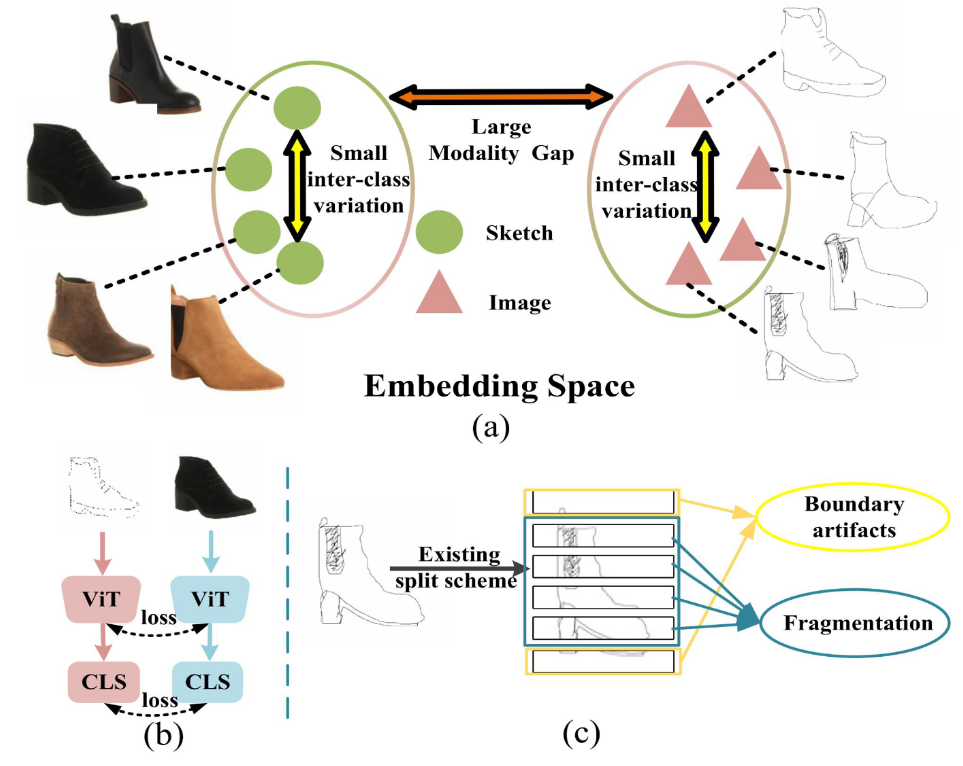
As shown in the figure above, the paper has two main motivations:
-
As shown in figure (a), existing methods only focus on single-modality feature extraction, ignoring the complementarity between sketches (structural outlines) and photos (texture and color). The characteristics of large cross-modal differences within the same instance and small intra-modal differences across different instances make direct alignment difficult. The complementary information between sketches and real images is not fully utilized.
-
As shown in figure (c), fixed-size patch partitioning produces boundary noise and fragments complete features. Meanwhile, the lack of cross-granularity feature interaction prevents the use of multi-scale contextual information to enhance discriminability.
The entire paper aims to solve these two problems.
2. Method
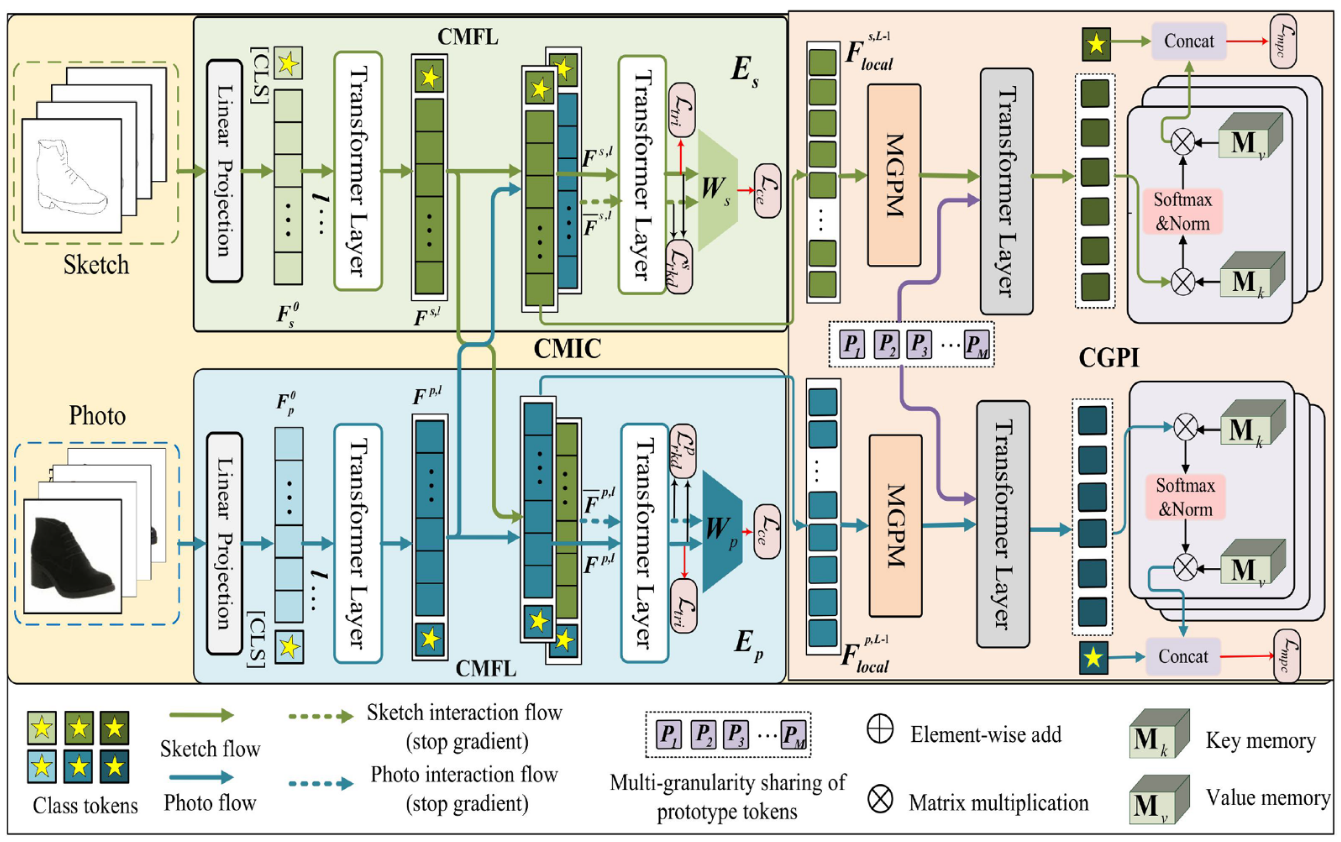
The figure above shows the overall framework of the proposed method. The framework is abbreviated as MCGI and can be roughly divided into 3 major modules: CMFL, CMIC, and CGPI. The CGPI module is further divided into three sub-modules: MGPM, CGII, and MGPC.
CMFL (Cross-Modality Feature Learning)
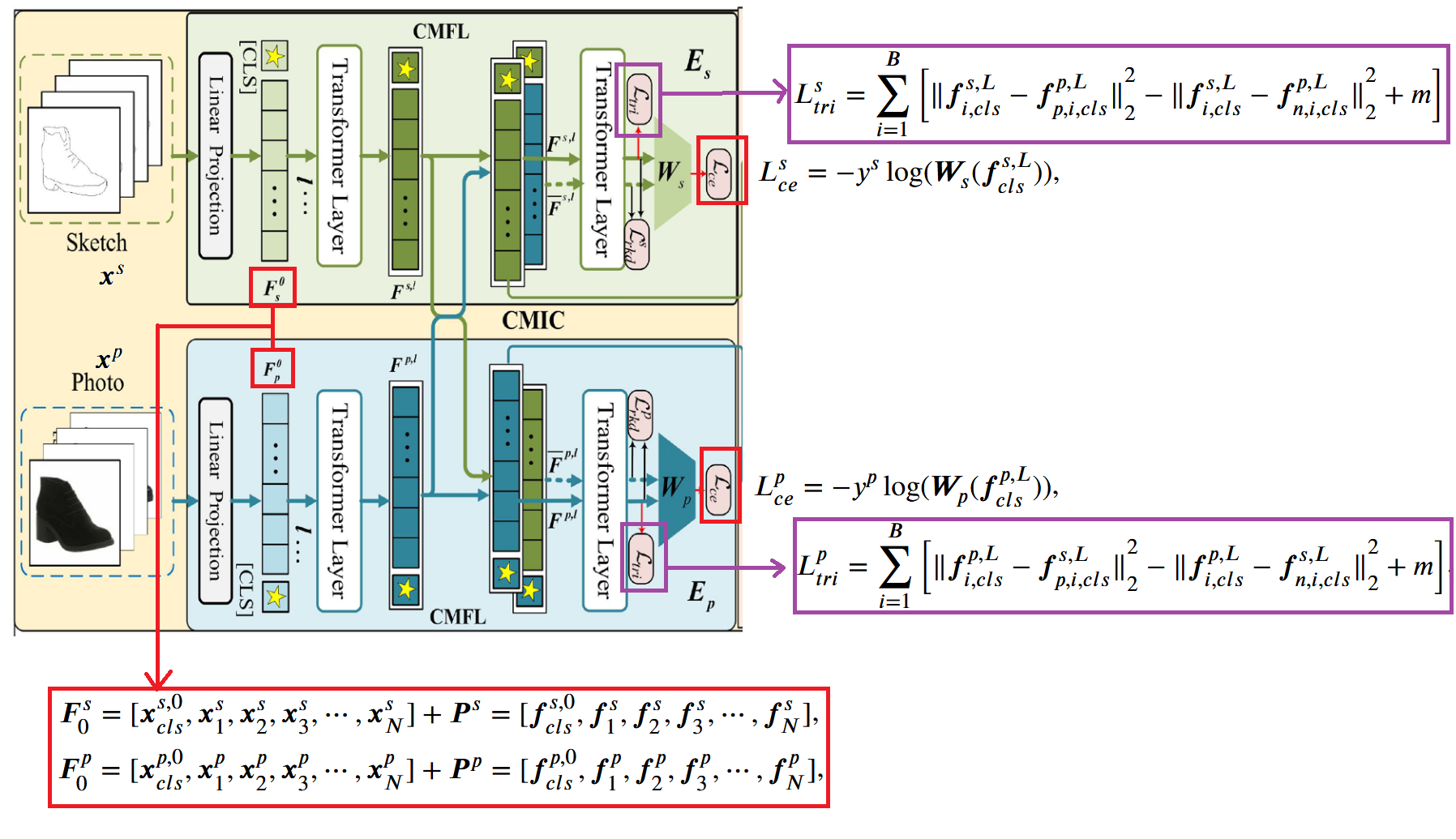
The cross-modality feature learning module is not the paper’s innovation point; it can be considered a baseline module. This part uses a ViT-B/16 encoder. Sketches or images are divided into tokens, and after adding position encoding and [CLS] token, they are separately input into the L layers (12 layers) of the encoder. The outputs are and (the former represents sketch, the latter represents real image). These two [CLS] tokens are then fed into classifiers and respectively, and cross-entropy losses and are calculated for the classification results. At the same time, basic cross-modal alignment is performed. The paper uses triplet loss with mutual alignment, calculating triplet losses and . The specific formulas are shown in the figure below:
CMIC (Cross-Modality Information Compensation)
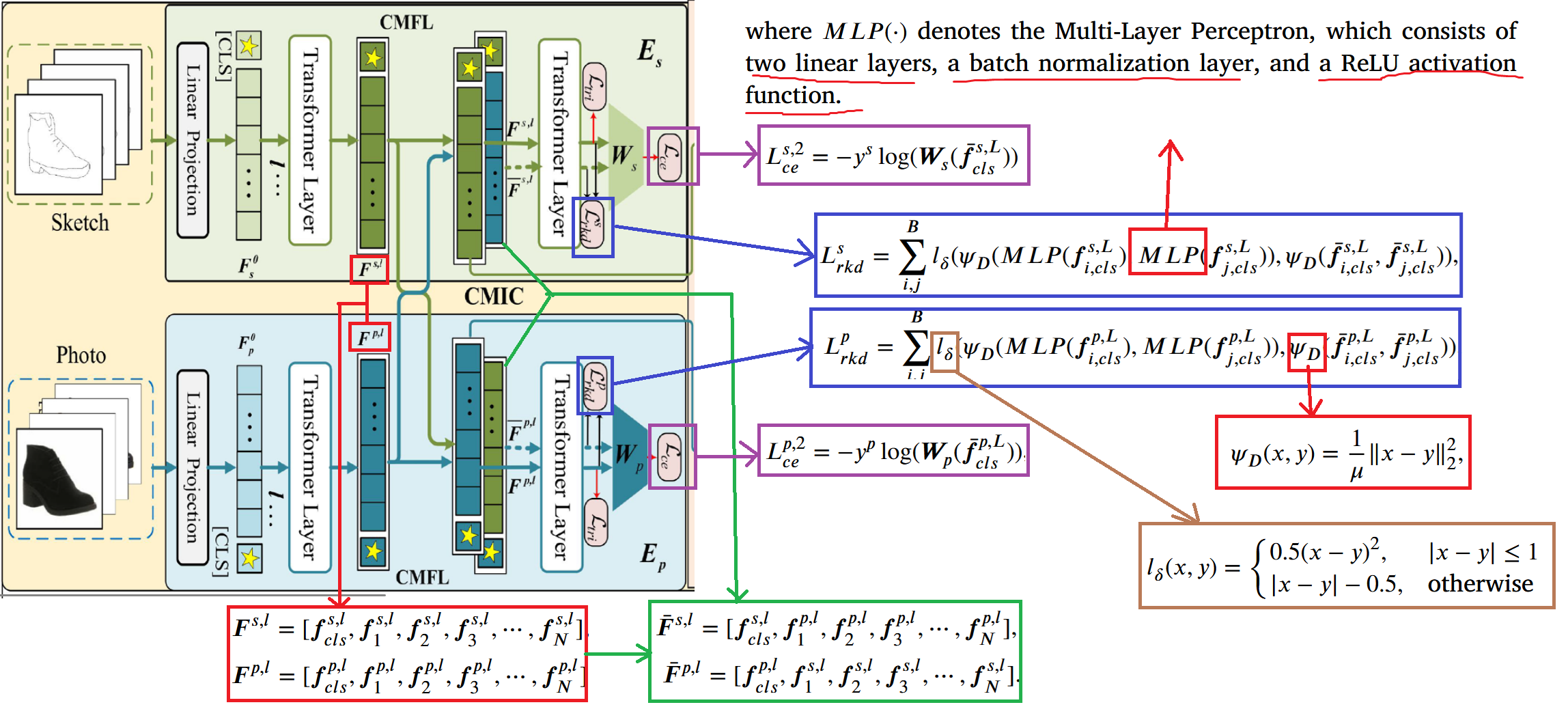
The cross-modality information compensation module is the first innovation point proposed in the paper to solve problem 1 in the motivation. The method involves exchanging tokens from the l-th layer output (the paper sets l = 11). The exchange method preserves the [CLS] token without exchanging it, only exchanging the N patch tokens. The token sets before exchange are denoted as and (the former for sketch, the latter for real image), and after exchange as and . Then the exchanged token sets pass through the remaining layers to obtain outputs. The [CLS] tokens from both sides are extracted, denoted as and , and these two tokens are used to calculate cross-entropy losses and following the same approach as CMFL.
However, there is an issue: while we know the pairing relationship between sketches and images during training, we don’t know the pairing relationship during inference. Therefore, the paper designs a relational knowledge distillation. The two [CLS] tokens output from the CMFL module: and are separately fed into two MLPs to simulate the output after token exchange, and loss functions and are designed for distillation. The specific formulas are as follows, where represents the distance function, represents the normalization factor for distance, and represents the Huber loss function.
CGPI (Cross-Granularity Prototype Interaction)
The cross-granularity prototype interaction module is the second innovation point of the paper, designed to solve problem 2 in the motivation. This module is further divided into the following three sub-modules.
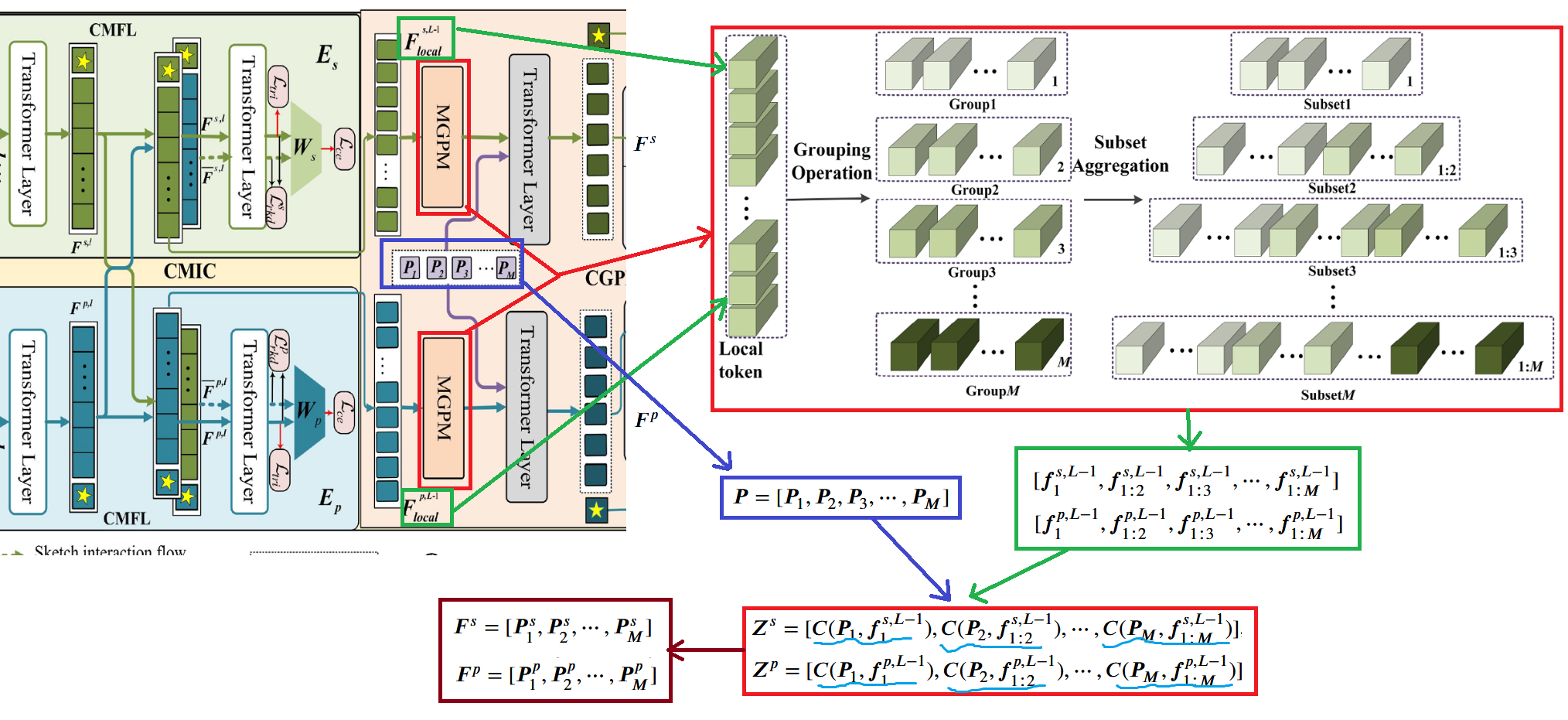
MGPM (Multi-Granularity Prototype Learning Module)
The multi-granularity prototype learning module has two abbreviations in the paper: MGPM and MGPL. The paper’s framework diagram uses MGPM, while the text description uses MGPL. For consistency and ease of explanation, I will use MGPM here.
This module takes the patch token output (excluding [CLS] token) from layer L - 1. The outputs for sketch and real image are and respectively. These are then evenly divided into groups (the paper sets ), with each group containing tokens. Then, these groups are progressively aggregated to form feature sequences of different granularities: and , where represents the concatenation of tokens from the first groups.
To enhance the discriminability of these multi-granularity features, the paper introduces learnable multi-granularity shared prototypes , concatenating each granularity’s prototype with corresponding local tokens: and , where represents the concatenation operation. These prototypes function similarly to [CLS] tokens, with each prototype responsible for aggregating the global feature representation of the i-th granularity.
Then and are separately fed into the L-th layer Transformer Encoder to obtain and . The detailed flow diagram and formulas are shown below.
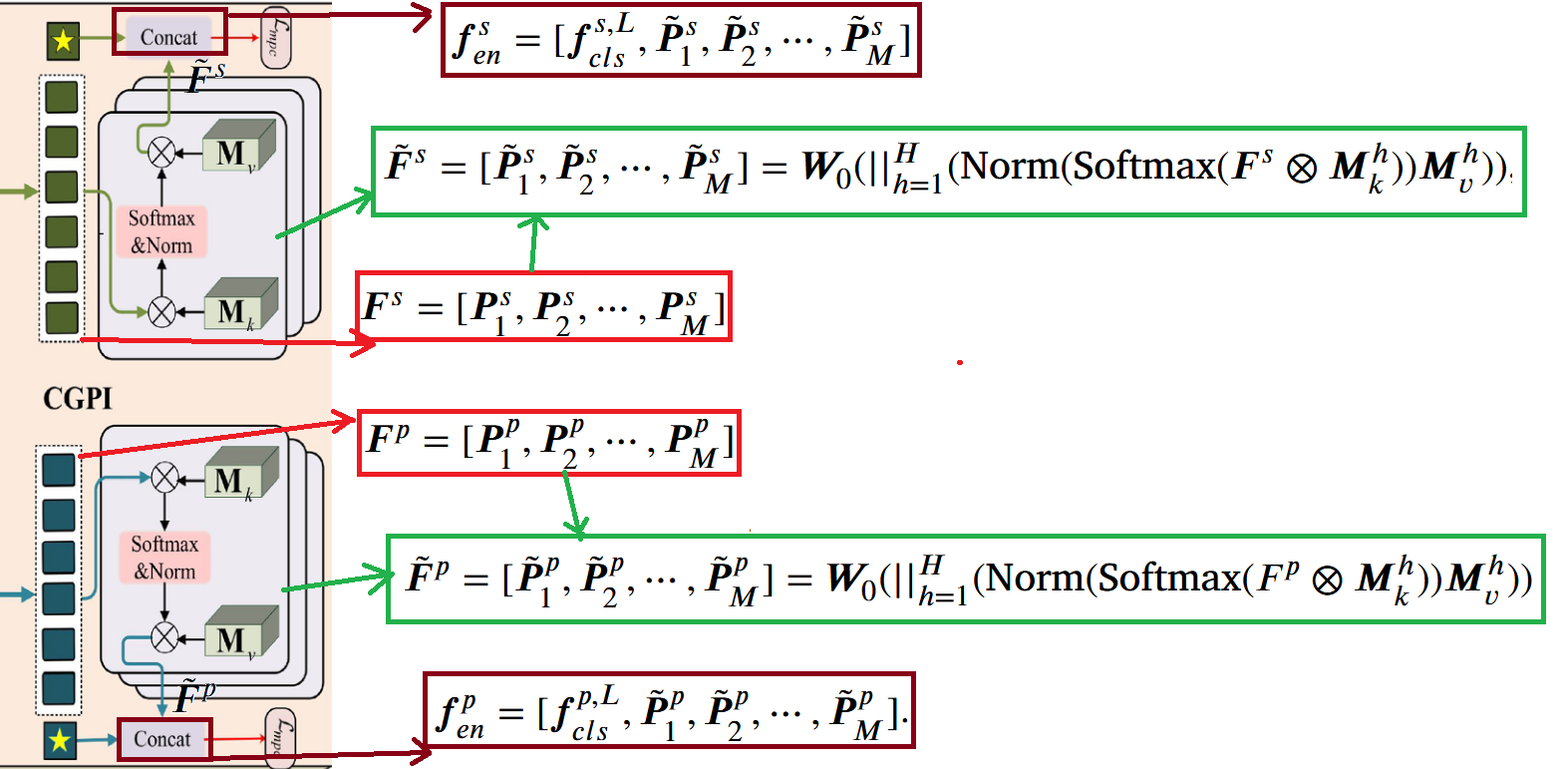
CGII (Cross-granularity Information Interaction)
The cross-granularity information interaction module continues to process the output from the previous module. This module introduces two external memory units and as Key and Value, using multi-granularity prototype features and as Query, and calculates cross-granularity attention weights to capture contextual associations between different granularities. Through multi-head attention mechanism, information from different granularities is aggregated, outputting enhanced multi-granularity features and . Finally, these are concatenated with the global [CLS] token to obtain complete enhanced feature sets and . The specific process is shown below:
MGPC (Multi-Granularity Prototype-aware Contrastive Loss)
The multi-granularity prototype-aware contrastive loss module uses the outputs and from the previous module to calculate contrastive loss for further alignment of cross-modal multi-granularity feature representations. This loss increases the similarity of positive sample pairs (matched sketch-photo pairs) in the multi-granularity feature space while decreasing the similarity of negative sample pairs, promoting feature alignment between sketches and photos at the multi-granularity level. The specific process and formulas are as follows:
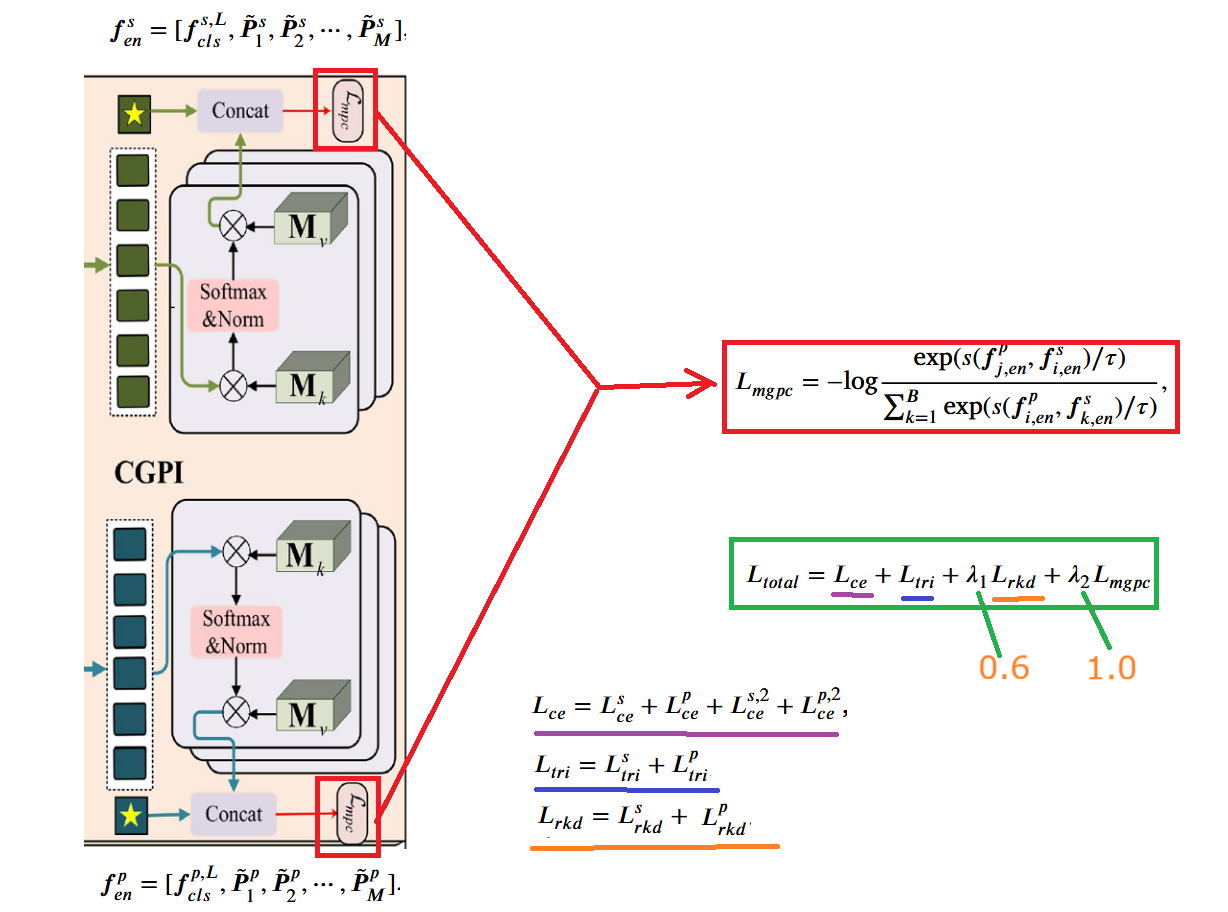
The total loss is the weighted sum of all the above losses, where and . The optimization of these two parameters will be explored in later experiments.
3. Experiments
Dataset Settings
The experimental setup uses four datasets:
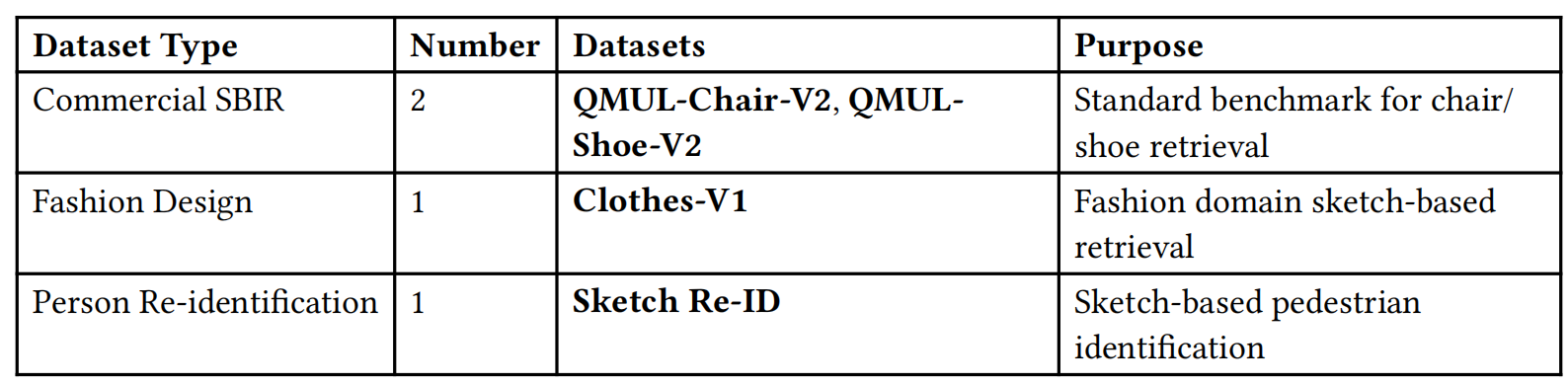
These are the chair dataset, shoe dataset, clothing dataset, and pedestrian dataset.

Comparison with State-of-the-Art Methods
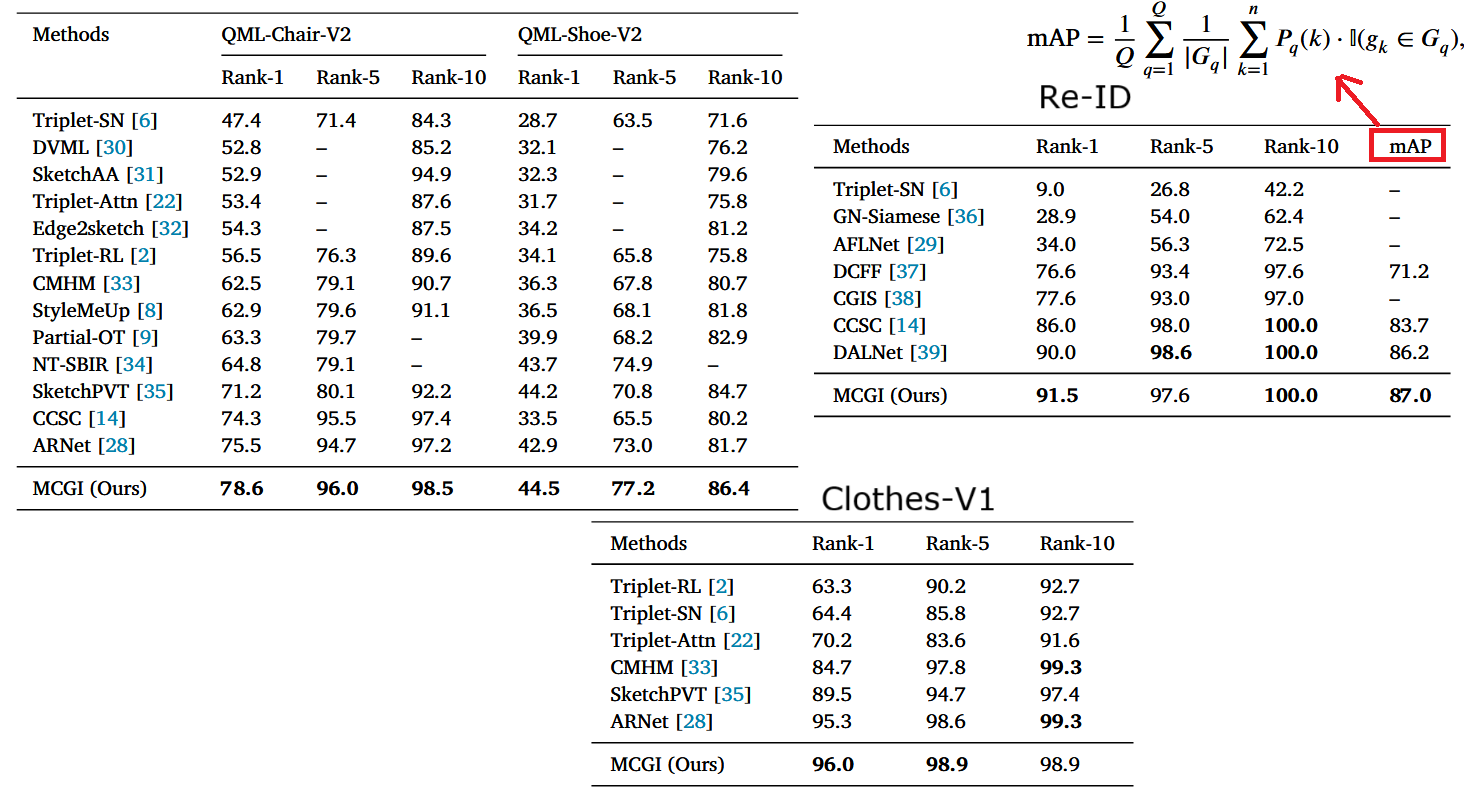
The three tables above show comparisons with current state-of-the-art methods on different datasets. The paper’s model demonstrates overall better performance, especially on the chair and shoe datasets, showing improvements across all metrics.
Ablation Studies
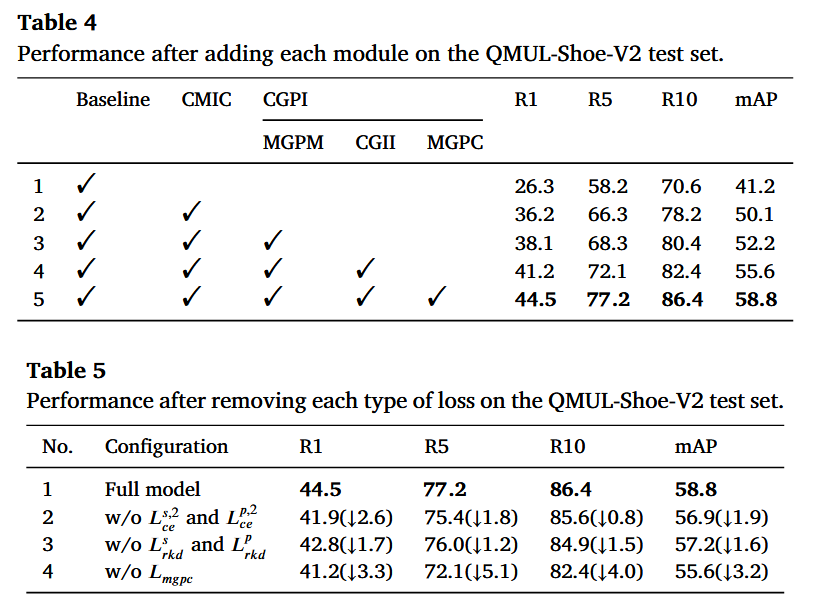
As shown above, the first table presents ablation study analysis on the shoe dataset, exploring the role of the four innovative modules proposed in the paper. The results show that metrics are highest only when all modules are used, indicating that each module is indispensable.
The second table provides ablation analysis for each loss function, also conducted on the shoe dataset. Removing any loss function leads to varying degrees of performance degradation. These results validate the effective contribution of each proposed loss function to the overall model performance.
Hyperparameter Analysis
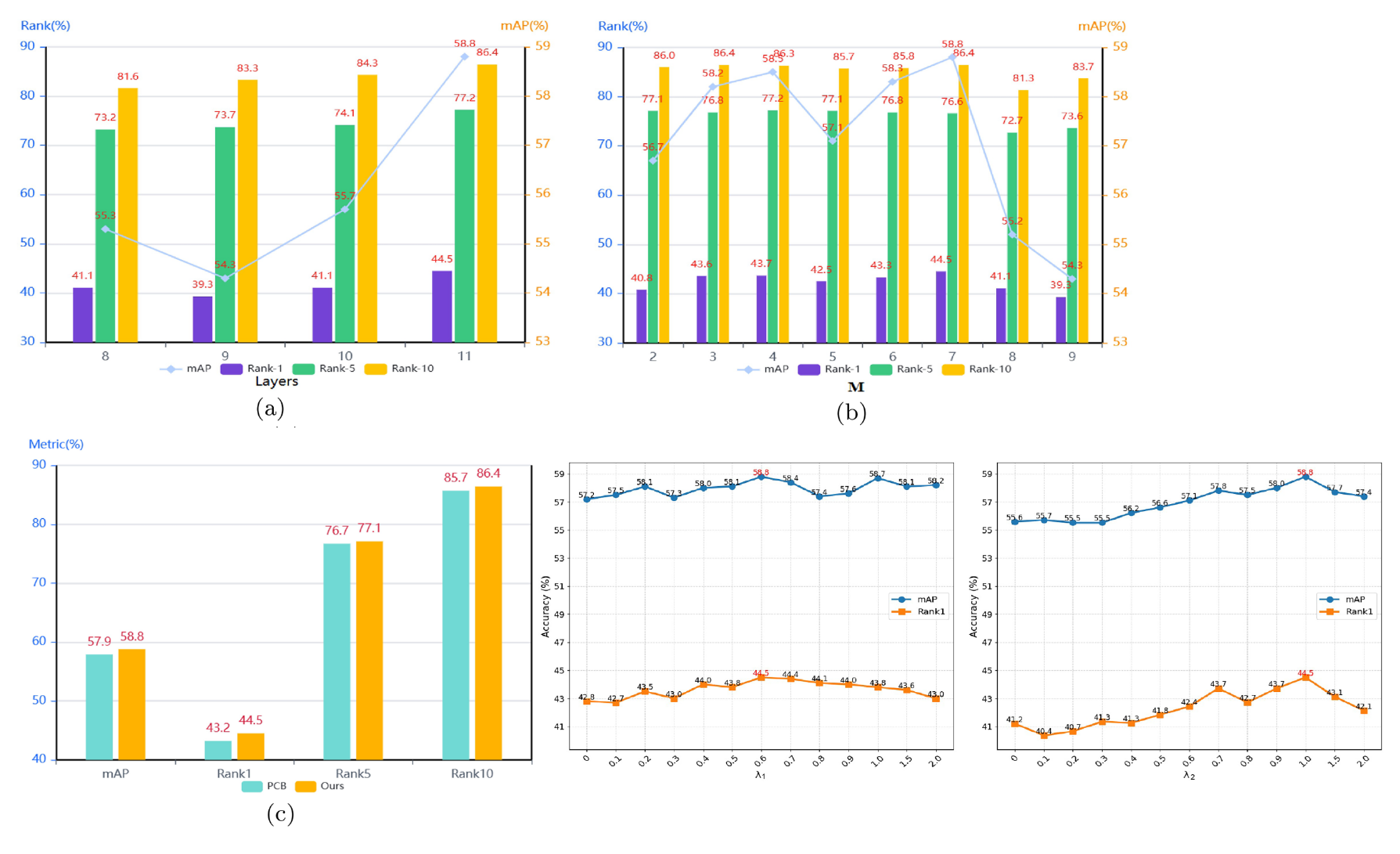
As shown above, figure (a) demonstrates the impact of token exchange at different layers on model performance. Experimental results show that as layer increases, accuracy and mAP gradually rise, reaching their peak at , which is why the paper sets .
Figure (b) shows the impact of multi-granularity number (i.e., the number of groups mentioned earlier) on model performance. Experimental results indicate that when , overall metrics are best with the highest mAP.
Figure (c) compares the performance difference between the proposed MGPM module and the traditional fixed patch partitioning strategy (PCB). Experimental results show that MGPL significantly outperforms PCB across all evaluation metrics, validating the effectiveness of the hierarchical granularity partitioning strategy. Therefore, the paper adopts MGPM as the multi-granularity feature learning method.
The last two line graphs experiment with the impact of and values on the experiments, showing that the best results are achieved when and .
Experimental Visualization

The figure above shows visualization of retrieval results using the proposed method on four datasets, where green boxes indicate correctly retrieved images and red boxes indicate incorrectly retrieved images. The method successfully ranks correct target images in higher positions. This improvement is evident across different types of datasets including chairs, shoes, clothing, and pedestrians, demonstrating the good generalization capability of the framework.
4. Conclusion
The MCGI framework addresses fine-grained sketch-based image retrieval by leveraging cross-modal complementary information and cross-granularity contextual associations, thereby bridging modality gaps and enhancing feature discriminability.
The Cross-Modality Information Compensation (CMIC) module integrates complementary information from sketches and photos through token exchange and knowledge distillation to learn modality-robust feature representations.
The Cross-Granularity Prototype Interaction (CGPI) module hierarchically extracts multi-granularity features and models their contextual interactions to capture discriminative fine-grained information.
Extensive experiments on four benchmark datasets demonstrate state-of-the-art performance, achieving 78.6% Rank-1 accuracy on QMUL-Chair-V2, 44.5% on QMUL-Shoe-V2, 96.0% on Clothes-V1, and 91.5% on Sketch Re-ID.
Ablation studies validate the effectiveness of individual components, where CMIC improves modality robustness and CGPI enhances fine-grained discriminability through hierarchical feature learning and cross-granularity interaction.